本篇记录一些杂七杂八的东东:x64,NASM,调用方式,栈帧,大小端~
X64
x86和IA-32差不多,x64和IA-64区别很大,我们遇到的是x64,它的通用寄存器大小变为64位,以R开头,增加了R8~R15寄存器,向下兼容可使用EAX、AX、AL,在本地模式下不再使用段寄存器。
Linux与Windows对x64处理器的使用方式也存在微小区别:
Windows
微软为了使32位程序在64位系统下运行提供了WOW64机制,在数据模型上,它只是将指针变成了64位(HANDLE也是指针),在API上,提供了32位与64位库但是调用差别是隐式的(system32/sysWOW64,注册表不同),它使用API勾取是程序员不会察觉有何不同,注意win64只能运行32位用户模式程序,不能运行内核模式级别的32位程序,实质上,他们最终还是被转换成了调用ntdll.dll 64位版本。
调用方式只有一种,类似fastcall,它最多将4个参数传入寄存器,超过则使用堆栈(此时堆栈仍然会保留前四个参数的空间,这个空间由调用者分配,因为调用者并不知道被调者是否需要使用这几个传参的寄存器),栈的大小比实际需要大很多,入栈不使用PUSH而是使用MOV指令。。。太多了,这篇记得这么详细,戳一下!
比较两种环境下的不同:
这里由于编译优化未使用栈帧,看出这里所有的参数都是压栈传入,由被调用者清理栈。
这里使用了寄存器传参,对照32位的可以看到,r9d为第四个参数(传入参数是从右到左,需要倒着来),rcx为第为第一个参数,r8d为第三个,edx为第二个参数,最上面有一个sub rsp,48h 是抬高栈顶,在CreateFileA中,第五个参数是栈里面第一个,为rsp+20h,是因为给前四个参数留了空间(4*8h=20h)。
它和PE32区别主要是与地址有关的值大小变大了!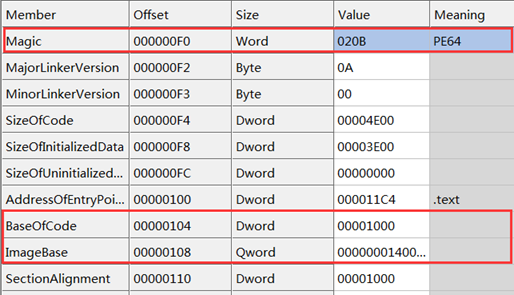
PE装载器通过magic判断是64位还是32位,imagebase为64位了,则可以装载到任意位置,但是BaseOfCode等值还是32位,说明一个映像最大仍然为4GB,还少了BaseOfData这个项,对64位文件进行查看,编辑可以使用CFF Explorer,它功能十分强大。
Linux
与Windows类似,在传参时也是优先使用寄存器,不过Windows使用的依次是rcx,rdx,r8d,r9d并且有零散空间,而Linux使用了6个寄存器,依次为rdi,rsi,rdx,rcx,r8,r9并且没有零散空间,这也意味着前六个参数存在寄存器,栈上返回地址之上开始为第七个参数。
汇编风格
Linux下默认是AT&T风格,它和Microsoft风格大体一样,不同点如下(它们只是风格不一样):
操作码明确指明了操作位数
1
2movl $10,%eax ;NASM
mov $10,eax ;MASM(误,语法错误)详细如下:
C声明 GAS后缀 大小(字节) char b 1 short w 2 (unsigned) int / long / char* l 4 float s 4 double l 8 long double t 10/12 目的操作数位置,如
1
2mov eax,ebx ;MASM
movl %ebx,%eax ;NASM寻址方式:
1
movl $0x12345678(%ebx,%edi,4),%eax
$0x12345678是基址,ebx是相对基址偏移,edi为序号,4为大小,即EA为$0x12345678+ebx+edi*4,当然在实际使用时并不一定每一位都用上,只要保持格式即可,例如
1
2
3movl (%ebx,%edi,4),%eax ;EA=ebx+edi*4
movl $0x12345678(,%edi,4),%eax ;EA=0x12345678+edi*4
movl (%ebx),%eax ;EA=ebx另外,间接寻址时,使用()而不是[]
1
2movl (%ebx),%eax ;NASM
mov [ebx],eax ;MASM常数前使用$修饰,寄存器使用%修饰,地址前使用*修饰
1
2movl $10,%eax
jmp *0x12345678一条常用的指令
1
2
3
4leave ;平衡栈帧
;等价于下面两条指令
movl %ebp,%esp ;平衡栈
pop %ebp ;还原ebp调用方式
栈帧

1 | base +-------> +-------+ |
函数内,栈帧套路:
1 | push ebp ; 将ebp压入栈 |
这样整个过程esp,ebp调用前后可保持不变,局部变量将被舍弃,即整个函数调用过程:
- 参数入栈 (PUSH)
- 返回地址入栈,跳转 (CALL)
- 上个ebp入栈 (PUSH EBP)
- ebp=esp形成新的栈帧底部 (MOV EBP,ESP)
- 执行各种操作
- esp=ebp (MOV ESP.EBP)
- 弹出栈顶即保存的上一个栈帧的ebp值到ebp(POP EBP)
- 根据栈顶值即返回地址返回(RET)
- 清理参数(根据调用约定,可能在返回时清理,也可能在返回后清理)
字节序
对于字节型数据,大小端序都是一样的(包括字符串),一般大型Unix服务器的RISC系列CPU,网络协议使用大端,Intel x86使用的是小端。
这里可以看出存储顺序:
0x12 -> 12 00 00 00
0x1234 -> 34 12 00 00
0x12345678-> 78 56 34 12
abcd -> 61 62 63 64 调用约定
为了保证函数的正确调用及调用后栈帧平衡的一套约定:
| 调用约定 | 关键字 | 参数入栈顺序 | 回收堆栈 |
|---|---|---|---|
| C规范 | __cdecl | 右到左 | 调用者负责 |
| 快速调用规范 | __fastcall | 右到左及寄存器传参 | 被调用者负责 |
| 标准调用规范 | __stdcall | 右到左 | 被调用者负责 |

这里依次使用__cdecl,__fastcall,__stdcall,默认 这几种调用方式,在调用者这里看,__cdecl和默认(其实就是__cdecl,在VC下默认stdcall)是自己清理栈,那么__fastcall,__stdcall为被调用者清理栈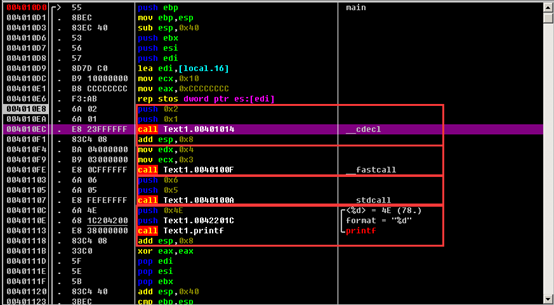
__stdcall被调用者内部看到,返回的时候清理了栈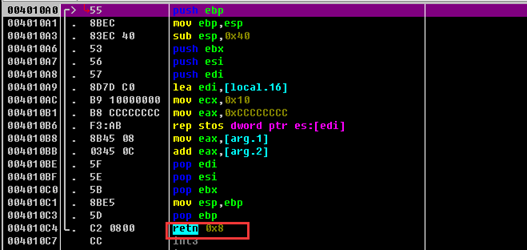
而上图不能看到__fastcall,因为它会先使用ECX,EDX寄存器,当参数少时不会用到堆栈。
入口点
这里的入口点不是EP,是程序初始化以后,执行第一条自己写的代码的地址。
1:入口函数特征
例如C写的,会压入3个或4个参数,一般会和GetCommandLine同级,后面会是Exit
1 | _tmain(int argc,TCHAR* argc[],TCHAR* envp[]) |

2:猜测最先执行的特征
例如首先输出的字符串,在那里下断点,然后直接向上知道函数起始点,也可通过栈回溯到上一层
3:层层递推分析
第一次一直使用F8步过调用
第二次先使用F7不如调用第一层后一直使用F8步过,返回上层继续使用F7
重复一层层的递推下去,知道找到入口点
4:使用ida自动分析