浪漫一下,复习下编译原理,本篇先记录下此法分析与语法分析部分~
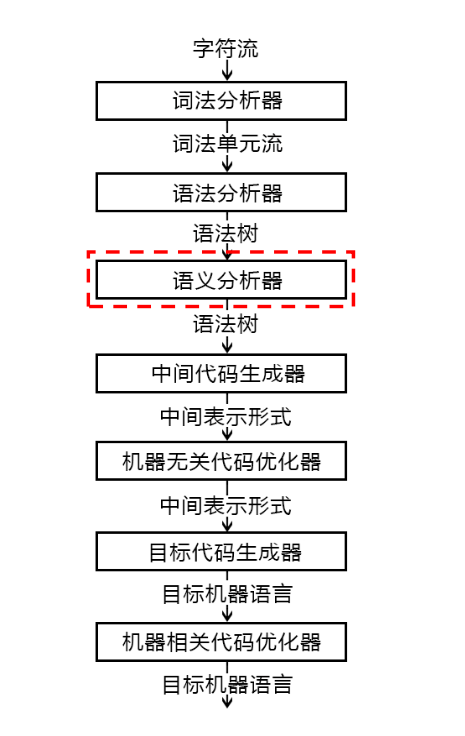
基本概念
字母表
字母表∑是一个有穷符号集合
字母表上的运算
乘积:$\Sigma_1\Sigma_2={ab|a\in\Sigma_1,b\in\Sigma_2}$
n次幂:
$$
\begin{cases}
\Sigma^0={\epsilon}\
\Sigma^n=\Sigma^{n-1}\Sigma,n\ge1
\end{cases}
$$
克林闭包:$\Sigma^*=\Sigma^0\cup\Sigma^+=\Sigma^0\cup\Sigma^1\cup\Sigma^2\cdot\cdot\cdot$
串
设∑是一个字母表,所有x∈∑*,x称为是∑上的一个串,|s|表示串的长度,ε表示空串
文法的形式化定义
$$G=(V_T,V_N,P,S)$$
推导与规约
推导:用产生式的右部替换产生式的左部
规约:用产生式的左部替换产生式的右部
句子与句型
句子是不包含非终结符的句型
Chomsky文法分类
0型文法 (Type-0 Grammar) :无限制文法(Phrase Structure Grammar, PSG )
1型文法 (Type-1 Grammar) :上下文有关文法(Context-Sensitive Grammar , CSG )
2型文法 (Type-2 Grammar) :上下文无关文法 (Context-Free Grammar, CFG )
3型文法 (Type-3 Grammar) :正则文法(Regular Grammar, RG )
分析树
推导的图形化表示,从左到右排列叶 节点得到的符号串称为是这棵树的产出( yield )或边缘(f rontier)
短语
给定一个句型,其分析树中的每一棵子树的边缘称为该句型的一个短语(phrase)
如果子树只有父子两代结点,那么这棵子树的边缘称为该句型的一个直接短语(immediate phrase)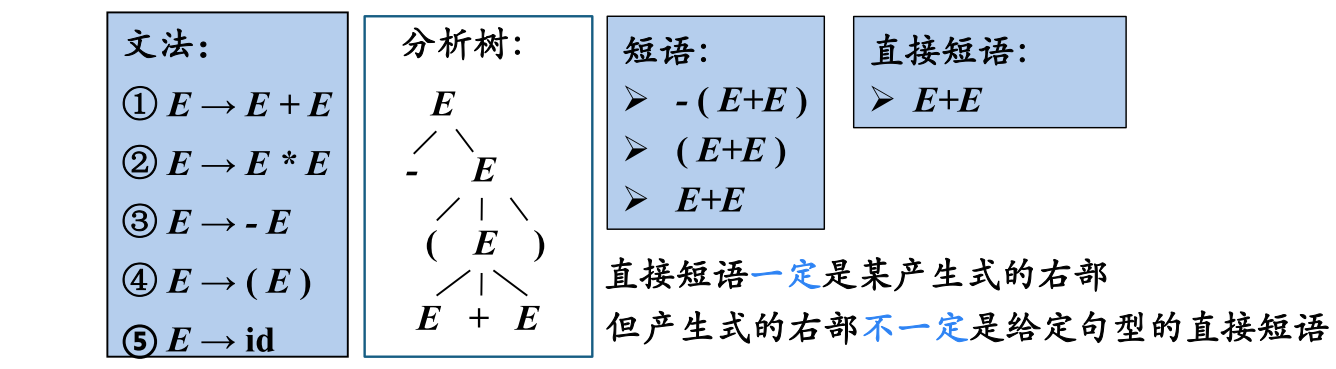
正则表达式
正则表达式(Regular Expression,RE )是一种用来描述正则语言的 更紧凑的表示方法
正则定义
给一些RE命名,并在之后 的RE中像使用字母表中的 符号一样使用这些名字,比如说定义数字:digit → 0|1|2|…|9
词法分析
FA
有穷自动机是对一类系统具有一系列离散的输入输出信息和有穷数目的 内部状态,只需要根据当前所处的状态和当前面临的输入信息 就可以决定系统的后继行为。每当系统处理了当前的输入后,系统的内部状态也将发生改变的系统建立的数学模型。它的表示为:
$$M=(S,\Sigma,\delta,S_0,F)$$
还需要记住的就是状态转换图: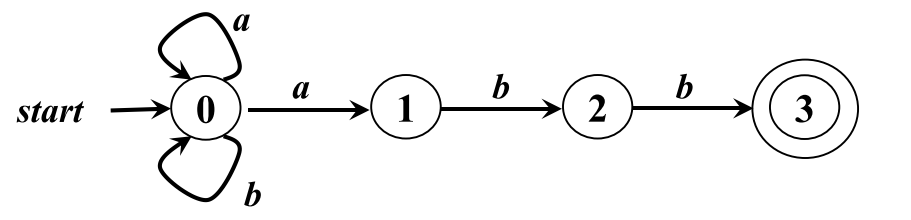
NFA
非确定的有穷自动机,在转换中有多种选择可做,下一步不确定。
DFA
转化
RE<>NFA<>DFA之间是可以转换的
RE->NFA
使用Thompson算法,基于对RE的结构做归纳:
- 对基本的RE直接构造
- 对复合的RE递归构造
复合结构即选择 连接 闭包,其他为基本结构,对于基本结构直接构造,即两个状态,中间使用字母连接转移,对于复合结构,递归构造的意思就是拆解为基本结构构造,再使用连接,例如典型情况: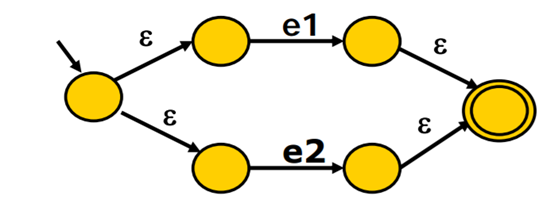
(e-> e1 | e2)
(e-> e1*)
NFA->DFA
使用子集构造算法,对于 a(b|c)* ,他生成的NFA如下图,由于空串的存在,在做状态转移时不能准确的知道应该怎么转移,可能会转移错误,于是需要回溯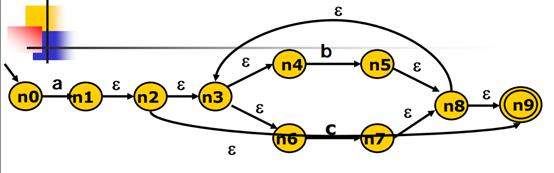
因此将它转换成DFA是很有必要的,而它的方法就是子集构造算法:
1 | q0 <- eps_closure(n0) |
1:eps_closure(x)表示x状态下的$\epsilon$闭包,因为$\epsilon$不需要消耗字母,即在x状态下不需要消耗字母就能到达的状态集合$q_0$,这个集合代表第一个状态,将其添加进Q这个集合,Q集合最初还是空的,此时也就只有$q_0$这一个元素.
2:同时把$q_0$添加进worklist这个集合,它此时也就只用一个元素$q_0$.
3:开始一个不动点算法,当worklist这个集合不为空,从里面取出一个元素q,再去用它遍历字母表中每一个字母,生成新的状态的$\epsilon$闭包$q_n$,如果新的$q_n$不在Q里面,就将它同时添加进Q和worklist
由于往worklist添加元素时,一定会往Q中添加元素,而worklist在每次的外层循环会弹出元素,状态的$\epsilon$闭包有限,这个不动点算法是一定会终止的!
这样的$q_x$就是新的状态了,它本来是原来的一些状态的集合,由于他们是$\epsilon$闭包,可以不消耗任何字母相互转移,所以将其认为是一个状态是没有问题的,显然,含NFA的初始状态的集合为新的初始状态,含NFA的终结状态的集合为新的终结状态。
至于eps_closure(x)的实现可采用深度优先搜索或广度优先搜索实现:
1 | /*基于深度优先遍历算法*/ |
还是容易理解,初始集合为空,执行到函数里面时首先将x状态加入闭包,再去遍历x能不消耗任何字母到达的y,如果y没有被遍历过,递归y…
1 | set closure = {}; |
DFA最小化
使用Hopcroft算法,将上面的NFA转换为DFA后,仔细观察发现还可以再化简: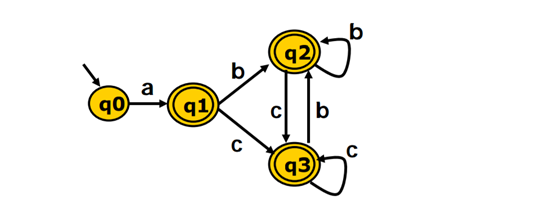
看到$q_2$和$q_3$其实是可以合并的,合并后的状态还可以和$q_1$再次合并,至于合并的方法,可以使用hopcroft算法,它首先将所有的状态分为接受状态和非接受状态两个集合,而这两个集合组成一个更大的集合A,此时集合A发生了变化,会进入while循环,A会将每个元素放入split函数去分隔,分隔方法是将元素遍历每一个字母,如果他们转移到不同的集合就说明可分割,就把元素再进行分隔:
1 | split(S) |
结合两个例子: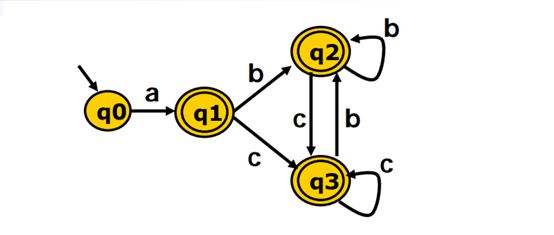
首相将$q_0$和$q_1$ $q_2$ $q_3$分成两个集合(接受状态与非接受状态两个集合),此时{$q_0$}是不可能再分隔了,{$q_1 q_2 q_3$}再遍历abc三个字母发现他们的状态仍然还在同一个集合,说明他们不可分隔,两个元素都遍历了,集合没有变化,算法结束,此时{q1 q2 q3}可以收缩成1个状态。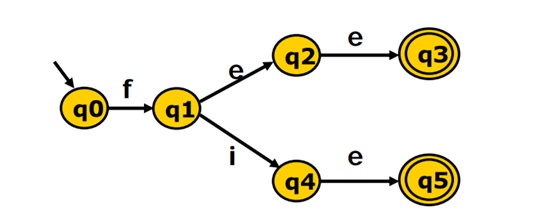
这个还是先分成{q0 q1 q2 q4}和{q3 q5}两个状态
第一轮:{q3 q5}不可接受任何字符,他们最终状态扔然还是在同一集合,即未拆分,q2 q4在输入e时转移到{q3 q5},而q0 q1输入e时仍然在{q0 q1 q2 q4},则他们分为{q0 q1},{q2 q4}
第二轮:由于集合发生变化,进入第二轮,由于q1输入e|i到{q2 q4},而q0仍然在{q0 q1},可分割,为{q0},{q1},其他的就不写了,最终状态就是这样。。。
错误处理
错误检测
如果当前状态与当前输入符号在转换表对应项中的 信息为空,而当前状态又不是终止状态,则调用错误处理程序
错误处理
查找已扫描字符串中最后一个对应于某终态的字符
- 如果找到了,将该字符与其前面的字符识别成一个单词。 然后将输入指针退回到该字符,扫描器重新回到初始状 态,继续识别下一个单词
- 如果没找到,则确定出错,采用错误恢复策略
错误恢复策略
从剩余的输入中不断删除字符,直到词法分析器能够在 剩余输入的开头发现一个正确的字符为止
语法分析
即给定文法G与句子s,判断给定句子s时候能够由给定文法G推导得出。
自顶向下分析
从文法G的开始符号出发,随意推导出某个句子t,比较t与s是否相等,若相等则说明s是G的句子,否则继续推导其他句子,若G推导出的所有句子都不等于s那么说明s不是G的句子。
1 | tokens[]; //句子s |
这是最直观的自顶向下分析,但是由于一个非终结符符可能有多个产生式,选错产生式需要回溯,效率不太高,若是能根据想要的结果(tokens中对应位的终结符)选择合适的产生式就能避免这种回溯,提高效率,这为预测分析。
文法转换
1: 在预测分析时,若只向前看一位,那么若同一非终结符的多个候选式存在共同前缀,仍然可能导致回溯,因为这样向前看的第一位并不能决定应该选择哪一个产生式,解决办法就是对产生提取左公因子,这就相当于跳过第一位从第二位开始向前看一位啦。
S → a A d | a B e
转换==>
S → S'
S' → A d | B e2: 左递归文法会使递归下降分析器陷入无限循环,解决方法是转换为右递归。
E → E a | e
转换==>
E → e F
F → a F | $\epsilon$LL(1)文法
它从左(L)向右读入程序,最左(L)推导,采用一个(1)前看符号,具有分析高效(线性时间),错误定位和诊断信息准确等特点,有很多开源或商业的生成工具,如ANTLR,。。。
算法基本思想:表驱动的分析算法,如图: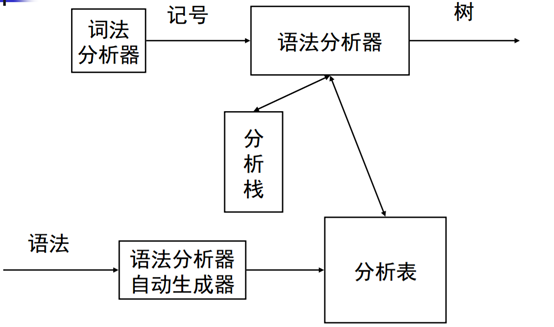
它和最原始的自顶向下分析算法很相似:
从文法G的开始符号出发,随意推导出某个句子t,比较t与s是否相等,若相等则说明s是G的句子,否则继续推导其他句子,若G推导出的所有句子都不等于s那么说明s不是G的句子。
1 | tokens[]; |
现在来看最重要的就是制作预测分析表了。
NULLABLE集
所有可以为空的非终结符组成的集合,这是一个归纳定义
非终结符X属于集合NULLABLE,当且仅当:
基本情况:X能直接退出eps
归纳情况: X -> Y1… Yn,其中Y1,…, Yn是n个非终结符,且都属于NULLABLE集
算法如下:首先初始化为空,当NULLABLE集还在变化时进行循环,它对每个产生式,若右部直接为$\epsilon$那么将左部并入NULLABLE集合,若右部全都是非终结符且每一个非终结符都在NULLABLE集合里面那么将左部并入NULLABLE集合,循环直到集合不发生变化:
1 | NULLABLE = {}; |
例如:
Z -> d
| X Y Z
Y -> c
|
X -> Y
|a第一轮:
运算Y时,NULLABLE集合为空,于是不能推出它为NULLABLE集合的,Y可以推出eps,那么Y加入,X可以推出Y,那么X加入
第二轮:
集合发生变化,成为{X,Y},那么继续循环,尽管X,Y是集合元素,但Z->XYZ是右递归,最右边一定是d,所以不可能属于nullable
循环结束,可知NULLABLE={X,Y}
FIRST集
FIRST(N) = 从非终结符N开始推导得出的句子开头的所有可能终结符集合计算公式,它是对于非终结符而言的。算法如下:
对于每一个非终结符N,初始first集为空,然后进入循环,对于每一个产生式,若右侧第一个为终结符,将其加入左部的first集,若是为非终结符,先将其的first集并入左部的fisrt集,再判断它是否属于NULLABLE集。。。
1 | foreach(nonterminal N) |
例如:
Z -> d
| X Y Z
Y -> c
|
X -> Y
|a由上面已知NULLABLEVT={X,Y}
第一轮:
FISRT(Z)={d}
FIRST(Y)={c}
FISRT()X={a,c}
第二轮:
FISRT(Z)={d,a,c}
FIRST(Y)={c}
FISRT()X={a,c}
第三轮:
集合不再发生变化,结果如第二轮。
FOLLOW集
对于每一个非终结符,能跟随它的终结符构成的集合。算法如下,初始为空,然后对于每一条产生式,从右到左推导,如果Betai为终结符,将其并入集合,Betai为非终结符M时,先把temp并入FOLLOW(M),再看M是不是属于NULLABLE集,若是就说明可以穿过。。
1 | foreach(nonterminal N) |
这里有点需要注意,对于一条产生式,初始时temp=FOLLOW(N),但他的目的不是计算FOLLOW(N),故从右向左遍历产生式时,若遇到终结符a,temp集合重置为{a},再继续遇到非终结符M,将其并入FOLLOW(M),若M输入NULLABLEVT那么将FIRST(M)并入temp,若不是,那么temp等于FIRST(M)。
再拿上面的栗子:
还是这个文法,左侧是之前算出来的,现在计算:
第一轮:
0:FOLLOW(Z)={}
1:FOLLOW(Y)={a,c,d},FOLLOW(X)={a,c,d}
…..
第二轮:
集合不会发生变化了,结束
FIRST_S 集
上面的都是相对于非终结符,而fisrt_s是针对产生式来说的,就是看每个产生式能以什么终结符开始,算法很简单:
1 | foreach(production p) |
预测分析表
根据FIRST_S集,根据产生式的左部字母与元素填充,看这张表就能理解了: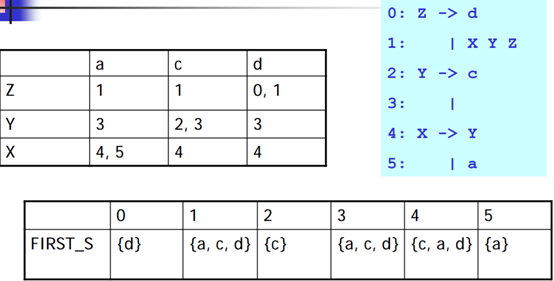
自底向上分析
语法制导翻译
参考
[1] 中国科学技术大学-《编译原理》
[2] 哈尔滨工业大学-《编译原理》