啦啦啦啦~
ida
ida使用的是数据库文件,在第一次分析binary时会生成它,并且之后的几乎所有操作都是对数据库的操作上,并且它的操作是不可撤回的。
复合结构
数组
不算吧,反正在首地址Edit->Array即可定义,对于伪代码可以Y来定义
结构体
直接看就懂了,主要问题是笔记本的del和ins键在一起,可以使用fn+del新建。
另外也可以使用local types来新建结构体,包含头文件也可以,只是需要自己手动将其添加进数据窗口。
错误
Decompilation failure: XXXXXX: call analysis failed Please refer to the man
类似的错误是因为不能正确识别函数原型,手动设置下函数类型即可,对于间接调用设置调用地址。
positive sp value
IDA会自动分析SP,寄存器的变化量,由于缺少调用约定、参数个数等信息,导致分析出错,Option→Generala中设置显示Stack pointer,然后去检查对应地址附近调用的函数的调用约定以及栈指针变化
cannot convert to microcode
部分指令无法被反编译,最常见起因是函数中间有未设置成指令的数据字节,按c将其设置为指令即可,其次常见的是x86中的rep前缀,比如repXX jmp等,可以将该指令的第一个字节(repXX前缀的对应位置)patch为0x90(NOP)
stack frame is too big
在分析栈帧时,IDA出现异常,导致分析出错。找到明显不合常理的stackvariable offset,双击进入栈帧界面,按u键删除对应stack variable;如果是壳导致的原因,先用OD等软件脱壳;可能由花指令导致,请手动或自动检查并去除花指令
local variable allocation failed
分析函数时,有部分变量对应的区域发生重叠,多见于ARM平台出现Point、Rect等8字节、16字节、32字节结构时尤其多见;修改对应参数为多个int;修改ida安装目录下的hexrays.cfg中的HO_IGNORE_OVERLAPS
F5分析结果不正确
F5会自动删除其认为不可能到达的死代码,常见起因是一个函数错误的被标注成了noreturn函数,进到目前反编译结果,找到最后被调用的函数(被错误分析的函数),双击进入,再返回(迫使HexRays重新分析相应函数);如果上述方案不成功,那么进到被错误分析的函数,按Tab切换到反汇编界面,按Alt-P进入界面取消函数的Does not return属性
调试
直接把idadbg文件夹下对应调试器放在目标环境并运行,然后选择调试器,在debugger->process options下设置调试选项: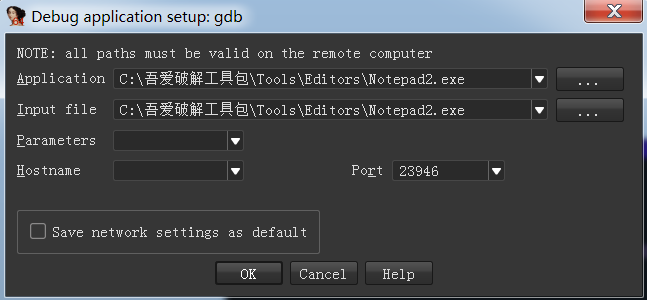
idc
ida提供的类C脚本语言,下面介绍也和C对照着来:
变量
变量区分大小写,需要先声明后使用,可在局部声明:
1 | auto addr,reg,valu=0; //局部变量 |
对于整数全部作为有符号数处理。
表达式
支持C里面除+= /= *= -=外所有运算,支持字符串赋值复制及切片:
1 | auto str1 = "what the fa?"; |
语句
支持C里面除switch外所有语句,支持try/catch/throw
函数
在idc文件中支持定义函数(idc命令行不行),函数参数是传值还是传引用有调用者确定:
1 | static printAB(a,b){ |
函数可以返回任意类型,若不显示指出返回0.
注释
插件
注意:安装插件时,若缺少dll最好去安装微软的运行时库而不要直接百度下载dll,不然将会被奇妙的问题带到奇妙的坑里
- keypatch:用来修改程序,也可以用来搜索指令。
- findcrypt:使用yara来发现加密算法中的常数
- ida_clemency:肝clemency的
- auto_re:增强标记
- sk3wldbg:一个基于unicorn的调试器
- lighthouse:神奇的工具,似乎很厉害,还不会用
- IDASkins:皮肤
- ida_nightfall:一种配色
- idastealth:对抗反调试的(三年没更新了)
- sig-database:用于识别静态编译的库函数
- ida-signsrch:通过特征识别函数,能够识别很多压缩、多媒体、密码算法、字符串、反调试等算法
- Ponce:
- idaemu:使用UNicorn进行模拟执行的,其实感觉和unicorn一样
- diaphora:用于diff,可以比较F5的伪代码,现在已经支持7.0啦
- bindiff:用于diff,目前只支持到6.8,但是很强大
- FRIEND:指令、寄存器扩展与帮助文档
- SimplifyGraph:一个十分好用的绘图工具,用于增强ida的流图界面
- HexRaysPyTools:自动创建结构体,类与虚表
- nao:简化一些没意义的汇编指令
例题
pwnhub-无题
想用这道题来练习下idc脚本编写,但是没找到原题的binary了,只能自己根据题目writeup描述自己写一个类似的并编译:
1 | gcc -fno-stack-protector -no-pie outfile.c -o test |
假装不知道漏洞在哪个函数里面,就写了下面的脚本来分析咯:
1 | for addr in XrefsTo(0x00400550, flags=0): |
1 | .text:0000000000435E7B public func_2314 |
可以看到溢出了0xf字节,比原题要多5字节
Z3
约束求解
微软的定理验证工具,就是约束求解的东西。约束求解就是对给定的符号一定的限制,然后求解出满足限制的具体值(一巴掌过来,不就是解方程组吗?),例如给定x,y:
x>1 x<y y<4,则可以求出x=2是它的一个解,这个过程就是约束求解,观察一类逆向题:”给定算法与输出,求输入”,一般来说这个给定的算法叫做加密算法,逆向要做的就是分析加密算法反推出解密算法,分析加密算法这里是读代码,而写解密代码就要考脑子想了,但若是使用约束求解就可以避免自己想,直接用工具就能求出。另外,约束求解给定的最简约束越多则运算速度越快,结果范围越小。
安装
pip install z3-solver
使用
1 | import z3 |
这是最基本的用法,其中,在一开始定义了两个python变量x,y它的类型是z3.Int,此时就可以把它们当作数学中的未知数,在接下来新建求解器并添加约束或者直接使用solve添加约束并求解。
angr
它是一个易用的二进制分析套件,可以用于做动态符号执行和多种静态分析,现在来简单记录一下它的用法,使用时也可以使用ipython的class?查看帮助文档。详细的文档可以看这里。
符号执行 (Symbolic Execution)是一种程序分析技术。其可以通过分析程序来得到让特定代码区域执行的输入。使用符号执行分析一个程序时,该程序会使用符号值作为输入,而非一般执行程序时使用的具体值。在达到目标代码时,分析器可以得到相应的路径约束,然后通过约束求解器来得到可以触发目标代码的具体值。1符号模拟技术(symbolic simulation)则把类似的思想用于硬件分析。符号计算(Symbolic computation)则用于数学表达式分析。
安装
- 安装虚拟环境
pip install virtualenvwrapper - 配置虚拟环境
1
2
3
4mkdir $HOME/.ven #创建工作目录
vim $HOME/.bashrc #编辑启动项
export WORKON_HOME=$HOME/.ven #将这两项放入文件,开机自动运行
source /usr/local/bin/virtualenvwrapper.sh - 使用虚拟环境
1
2
3
4mkvirtualenv env1 #创建环境
workon #列出已有环境
deactivate #退出环境
rmvirtualenv #删除环境 - 安装angrangr功能很多,最好使用ipython自动补全,在虚拟环境ipython可能会缺少部分库,重新安装即可。
1
2
3
4
5
6
7
8
9
10
11mkvirtualenv angr
pip install ipython #非必要
#pip install matplotlib networks #画CFG的
pip install angr
#安装angr-utils
mkdir angr-dev
cd angr-dev
git clone https://github.com/axt/bingraphvis
pip install -e ./bingraphvis
git clone https://github.com/axt/angr-utils
pip install -e ./angr-utils使用
下面使用如下样例测试:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
int main()
{
char passwd[] = "B3taMa0_Passwd_@Angr";
char input[30] ={0,};
puts("input passwd:");
scanf("%20s",input);
int len = strlen(input);
if(len == strlen(passwd)){
for(int i=0;i<len;i++){
if(input[i]!=passwd[i])goto error;
}
puts("success!");
}else{
error:
puts("error!");
}
return 0;
}创建项目
创建项目是使用angr的第一步,它会执行基本的分析操作。正常执行一个可执行文件,需要装载器按照其格式(如PE32或ELF)解析它并将其装载到内存中,其后CPU就可以直接执行它了;但是在做逆向分析时我们需要考虑的更多,即用同样的源码编译成的同样格式的可执行文件(如ELF),编译的目标架构(如x64,i64,mips,arm等)不同它的指令也是不同的,而我们在分析程序时关注的是程序的语义,为了消除这种差异可以把不同的原始的机器指令转换为相同的中间指令,再分析它的语义,这样只需要编写分析中间代码的工具而不需要为每一种指令编写分析工具,将会省去很多重复的工作,以上也即angr创建一个项目的过程:装载二进制文件->转换二进制文件为中间语言->转换IR为语义描述->执行真正的分析。由于我们在分析二进制程序时更多的是关心程序本身逻辑而非其使用的开源库,所以对动态链接库可以依实际选择是否装载。当不加载时,将无法使用它的导出函数,程序将无法正常运行,解决办法就是使用1
2import angr
proj = angr.Project('test', auto_load_libs=False,except_missing_libs=True)SIM_PROCEDURES或者hook,因为我们不关心程序运行后的影响,我们只关心程序本身逻辑,所以可以使用虚假的函数代替真实的函数,虚假的函数只改变程序的状态,模拟原函数的功能,例如我们需要调用read(0,buf,30)读取数据到buf,那么可以在python层写个虚假函数,它直接改变buf这块内存的数据及相应寄存器,不进行真正的io操作,这样就避免了分析库函数造成的路径爆炸等问题,angr把这中虚假函数叫做SIM_PROCEDURES并且已经实现了部分常用的虚假库函数,若没有也可以字节写。另外使用hook也可以达到相同的效果(unicorn就是使用hook实现处理库函数调用的)。另外就是hook也很常用,用法如官方用例:当项目创建完成,将能够得到很多有用信息,余下的操作都是根据这个项目实例来的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15stub_func = angr.SIM_PROCEDURES['stubs']['ReturnUnconstrained'] # this is a CLASS
proj.hook(0x10000, stub_func()) # hook with an instance of the class
proj.is_hooked(0x10000) # these functions should be pretty self-explanitory
True
proj.unhook(0x10000)
proj.hooked_by(0x10000)
<ReturnUnconstrained>
@proj.hook(0x20000, length=5)
def my_hook(state):
state.regs.rax = 1
proj.is_hooked(0x20000)
True
装载器
它负责解析加载可执行程序,于是所有程序的信息与加载信息都可以从这里得到:
如图,可以得到被装载的每个对象,对指定对象可以得到段与节区信息,也可以得到一些保护信息,获取符号信息。分析流图
自己的版本好像和文档的不一样,暂时用不上,有时间再去研究吧。可以看https://docs.angr.io/built-in-analyses/cfg 发出来的控制流图还是挺好看的:1
2
3
4
5
6
7import angr
from angrutils import *
proj = angr.Project("test", load_options={'auto_load_libs':False})
main = proj.loader.main_object.get_symbol("main")
start_state = proj.factory.blank_state(addr=main.rebased_addr)
cfg = proj.analyses.CFGFast()
plot_cfg(cfg, "test_cfg", asminst=True, remove_imports=True, remove_path_terminator=True)指令分析
angr的其他分析功能全部都需要下加载要分析的可执行文件以后再初始化对应的类对象,为了方便angr提供了工厂类获取这些实例对象: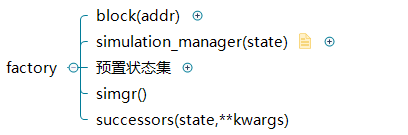
而其中的block方法即可查看分析指令,它指定一个地址作为参数,返回地址所在方法实例:
详细依然可使用ipython查看文档。
符号执行
这也是angr最重要的功能,它可以使用符号代替真实数据执行程序,出现分支即添加约束,路径也再加倍,最终探索到需要的路径时,就可以按照整个路径上的抽象语法树生成约束,使用求解引擎(如Z3)自动完成求解,得到能到此路径的输入。
angr可以指定一个地址开始执行,但是一个程序要正确执行直接给定任意地址是不行的,还需要给定此时的上下文(寄存器)及内存数据,angr把内存和所有寄存器信息合在一起称为一个状态集State,用它就可以表示程序执行的某个状态了,angr预置了三种状态起始也可以手动指定函数调用创建起始状态:
1 | entry_state() #最常用,从main object的entrypoint开始 |
我们可以通过状态看到程序的运行时数据,比如寄存器,内存,输入出调用栈等: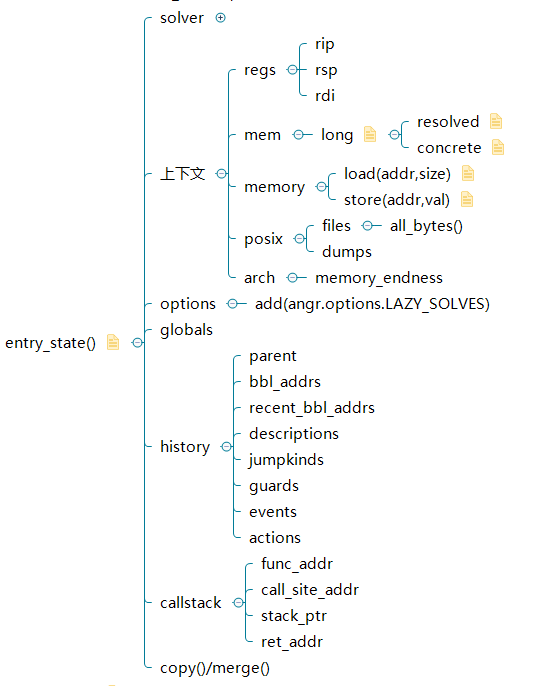
得到一个起始状态后就可以让程序从此状态开始符号执行了,而每执行一步将又会得到新的状态,angr使用simulation_manager来管理所有状态: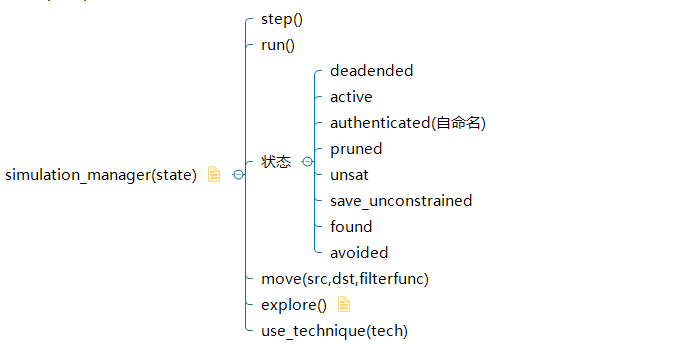
这里面最常用的就是explore,它能从当前状态开始探索路径,它有两个重要参数find后接地址或地址列表表明希望达到的地址,avoid恰恰相反表明不想要到达的地址,当执行此方法后,可以查看状态,found为找到到达find所指地址的路径,此时就可以使用约束求解得到到达该路径的输入了。至此,可以将样例的程序解出来了:
1 | import angr |
结果:
1 | (angr) ➜ ~ python testAngr.py |
约束求解
angr将抽象语法树转换为约束并求解,这是一个自动的过程,所以用户一般是不需要手动运用这个功能的,不过有时也需要用到,angr后端默认使用z3引擎求解。
数据定义
约束求解的整个运算对象是未知数,作为未知数它的值并不确定它只是一个符号,我们不能用传统的方法直接用定义普通变量来定义它,z3定义了对应的类,angr作为一套框架,为了方便使用不同的求解引擎,可以对这类符号极其运算做了抽象,由claripy模块暴露出抽象的接口,单独使用此模块的功能需要手动导入它,也可以从状态集里面获得sovler,sovler也可以定义符号与执行运算,以下介绍全是它的属性方法。另外,不同的符号代表的含义不同,他们的类型也根据实际变化,于是可以定义如下类型符号:
BVS即(bit vectors symbol),用它来表示一个符号,第一个参数表示符号名,第二个参数表示这个符号的长度 单位bit。当它参与运算后,将会得到一颗抽象语法树,可以使用args和op属性遍历该树。
BVV即(bit vectors value),用来表示一个明确值的整数,第一个参数为实际值,第二个参数表示值的长度。他可以直接与普通常数或同长度BVV进行四则运算,不同的BVV需要先进行位扩展再运算。
FPV即浮点值,用来表示一个明确值的浮点数,作为浮点数,它是不精确的而且有多种标准,需要用第二个参数指明。
FPS即浮点型符号,用来表示一个浮点型符号。
运算类型
可进行普通数学运算,默认比较运算会被当做无符号数,可以使用带SLE这类进行有符号数比较: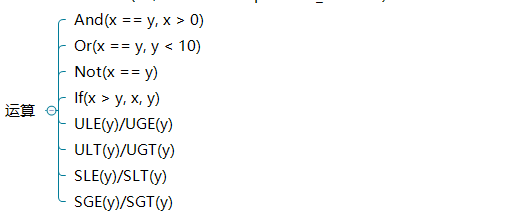
当然它也支持有符号除模等其它运算,详见文档。
求解

add()用于添加约束条件,satisfiable()用于查看是否有解,若有解可使用eval获取解,它的作用是将bitvector转换为python本地数据类型,它的参数指明要获取的是哪个未知数的解,参数也可以是多个未知数的表达式,这会取出相应未知数的解并进行运算再得值。
例子
见:https://github.com/angr/angr-doc/tree/master/examples?1549085924935
参考
ltrace/strace
跟踪用,能够轻易看出问题原因:
1 | ltrace |
nasm
1 | nasm -felf32 shell.asm -o shell.o |
*cat
用来监听的
1 | socat tcp-l:6666,reuseaddr,fork exec:"./pwn" |
readelf
喜欢它的格式,比较清晰~
1 | SYNOPSIS |
objdump
功能要更强大丁丁~
1 | OBJDUMP(1) GNU Development Tools OBJDUMP(1) |
参考
frida
frida是一款动态二进制插桩工具,有如下特性:
- 工作的对象可以实原生程序,也可以是jvm或者ObjC
- 它本身可以在所有主流操作系统上运行
- 它将一个v8引擎注入到目标内存,用户可以轻松的通过js操作目标进程
- 它合入了tinyCC,可以插入C代码提升效率。
- 底层用C实现,可以轻松实现其他高级语言的binding,现在有node和python的实现了
- 只在最初注入agent时才使用调试指令,之后直接使用管道和目标进程通信,不再使用调试api
注入原理
它有两种注入方式:
- 二进制注入,使用调试指令
- 源码注入
它们都不需要修改系统(和xposed不同),此处说明二进制注入^3:
- 获取权限,这在windows下需要管理员权限使用
AdjustTokenPrivileges获取调试权限,Linux为root即可 - 使用如
ptrace或OpenProcess调试函数附着目标进程,此时会劫持其线程 - 在被劫持线程上,调用mmap等获取一片内存,该内存需要有读写执行权限(由于操纵其他进程,此时需要解析其地址)
- 将bootstrapper代码注入该区域
- 执行bootstrapper后,它会装载
frida-agent并创建新线程去执行它 - 恢复原线程,此时完成
frida-agent注入,它以一个单独线程运行,并使用命名管道与客户端通信。
Linux上关键部分的代码如下,它位于frida-core分支:
1 | /* 附着到目标进程上*/ |
bootstrapper代码如下:
1 | // 创建并执行新线程并陷入返回调试器 |
现在,frida-agent已经注入并作为一个新线程运行,这对原程序是无感的(不是说隐蔽的),并且由于在同一进程,通过命名管道,客户端可以轻易的下发指令操作目标进程。
环境准备
最好使用python3+venv
1 | pip3 install frida |
此时安装了frida的核心,python binding与python的易用工具,其中frida-ls-devices可用于列出可用设备,frida-ps可查看指定目标运行的进程等。在客户端上,一般不需要在python层面做什么,比如用如下代码即可完成一般功能:
1 | import frida |
若安装node binding可以使用如下代码
1 | ; |
gumapi
这是核心所在,它的官方文档特别详细,可以分为如下几类:
- 类型:
- 进程:
Live inspection of other processes
○ no source code
○ no debugging symbols
● “Inject” our own agent D into the remote process P without
P noticing, and communicate with D from the outside of
process P
● Inspect and modify memory, threads, registers
● Avoid anti-debugging defenses
attaching to processes
● hooking functions
● modifying function arguments
● calling functions
● inspecting memory
● modifying memory
- Inject
a. insert our own custom logic into remote process - Intercept
a. trap function calls in remote process - Stalk
a. instruction-level code tracing in the remote process
b. avoiding all current anti-debugging products