除夕快乐翻了下博客发现去年除夕正在复习汇编语言,今年的话,看看能不能把这篇写完吧,下午要去找老朋友玩,若今天没写完下次再写应该就是数月后了,因为。。。我的毕设还没动,哇的一声哭了出来,接下来就要全力弄毕设和找工作了,忙忙忙
fuzz fuzz是软件测试的一种方式。程序能够对输入进行处理并做出相应的输出,在软件测试中我们会想要让测试用例尽可能完全覆盖代码(如完全的语句覆盖,完全的路径覆盖等 ),以极大限度的检测出软件的缺陷,在测试(黑盒)过程中代码是不变化的,测试的关键在于测试用例的选择,所以生成高质量的测试用例是测试的关键,相关的方法有边值分析等价划分等,输入测试用例再检测其输出是否符合预期即可检测程序缺陷,而fuzz就是这么一种技术,它能根据一定的规则自动化地生成大量测试用例,使用测试用例对程序进行测试,并监控程序执行状态,最终对输出归类(如归为是否crash )。
生成高质量的测试用例
执行程序并将测试用例输入
检测程序输出状态(不仅仅真正的IO输出,还包含程序状态变化 )
afl fuzz工具很多,而afl是一款十婚神奇的fuzz工具 ,它基于编译时插桩(也支持在Linux下使用QEMU进行运行时插桩的黑盒测试 ),既简单又高效,当然它主要设计为文件fuzzing,若对其他进行测试需要对代码进行修改。
安装与初体验 它的主体安装很简单,只需要执行以下命令即可:
1 2 3 4 5 wget http://lcamtuf.coredump.cx/afl/releases/afl-latest.tgz tar xvf afl-lastest.tgz cd afl-lastestmake make install
额外的,若需要使用QEMU进行黑盒测试,需要进行如下安装:
1 2 3 4 5 6 7 cd qemu_modeapt install libtool -y apt install bison -y apt install libpackagekit-glib2-dev -y ./build_qemu_support.sh cp ../afl-qemu-trace /usr/local /bin
当遇到static declaration of 'memfd_create' follows non-static declaration错误,可参考如下解决方案 :build_qemu_support.sh中的patch部分添加:
1 2 3 4 5 131 patch -p1 <../patches/elfload.diff || exit 1 132 patch -p1 <../patches/cpu-exec.diff || exit 1 133 patch -p1 <../patches/syscall.diff || exit 1 134 patch -p1 <../patches/memfd.diff || exit 1 135 patch -p1 <../patches/configure.diff || exit 1
2.在patchs目录下添加两个文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ➜ qemu_mode cat patches/configure.diff --- qemu-2.10.0-rc3-clean/configure +++ qemu-2.10.0-rc3/configure @@ -3923,7 +3923,7 @@ fi memfd=no cat > $TMPC << EOF - + int main(void) { ➜ qemu_mode cat patches/memfd.diff --- a/util/memfd.c +++ b/util/memfd.c @@ -31,9 +31,7 @@ - - - +
现在来试试能不能让程序跑起来:
1 2 3 4 5 6 7 8 9 10 11 12 13 wget http://www.ijg.org/files/jpegsrc.v9c.tar.gz tar zxvf jpegsrc.v9c.tar.gz cd jpeg-9c./configure CC="afl-gcc" CXX="afl-g++" --disable -shared make cd ..mkdir in_dir echo 'hello' >in_dir/helloafl-fuzz -i in_dir -o out_dir ./jpeg-9c/djpeg
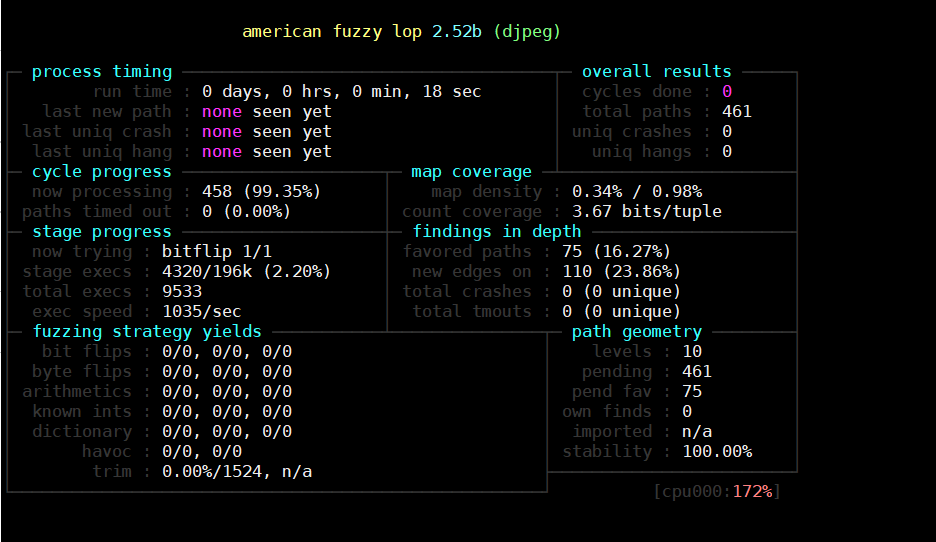
运行成功会出现如下界面:
原理 在详细介绍它的用法前先学习它精妙的实现思路!
测试用例 对于输入格式是高度结构化文件的程序,大多数情况下输入应该是符合某种规则而非完全随机,换句话说测试用例符合某种规则后测试将会变的更加高效,例如对office word进行测试,它的输入是一个文件,当然我们是可以任意指定被测试的输入文件的内容的,但是若它的内容为随机数据那么绝大多数条件下都不能满足以\xD0\xCF\x11这种正确的doc文件格式开头,也即在word在解析文件的第一步就会判断出输入有误而转向”唯一”的一条错误处理路径,只有极少数情况会满足doc文件条件而继续探索(一般错误情况数总是远大于正确情况数 ),之后的解析过程同样如此(乘法原理 ),因此这种随机数据作为测试用例无疑是极其低效的,为此我们需要了解doc文件格式,划分等价类只测试相对较少的不符合doc格式的数据,这样能用更少的数据覆盖更多的代码,一句话就是我们需要以合法的输入参照来生成测试用例。如文件数据结构 ),再依照此格式编写测试用例生成规则,这对于工具是友好的但是无疑大大加大了人的工作量,而afl使用了比较聪明的办法,它能通过一些算法自适应的生成符合合法输入的测试用例,也就是说最简单的我们可以以任何数据作为初始测试用例,不用再编写其它规则,afl就能正常工作!
怎么做到这一点?它的思路就是①监控被测程序的每一个分支执行 :输入改变程序执行路径,②路径信息作为反馈指导产生新的输入 ,将一个程序以条件分支分为很多个小的部分,以分而治之的思想就能将指数级测试测试优化到线性级。显然AFL的实现主要就要实现上面两件事。
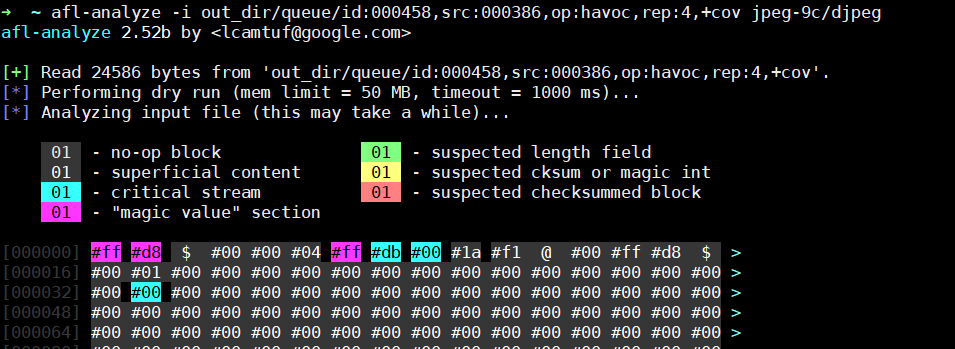
afl-analyze 在介绍上面提到的两个任务实现方法前先插入afl其中的一个工具的介绍,顾名思义它是用于分析,他能够以指定输入为基础对程序进行分析识别出程序合法输入的轮廓!
1 afl-analyze -i out_dir/queue/id:000458,src:000386,op:havoc,rep:4,+cov jpeg-9c/djpeg
运行结果如下:
将某些内容定义为非操作块(no-op blocks):当数据发生变化时控制流不会变化,例如一张图片像素部分的值变化不会改变程序执行流。
校验和,魔数等:当数据发生一点变化就会使程序进入相同的逻辑(如校验失败则程序退出)。
更长的整体数据块:他们可能被计算校验和或者是密文数据。
纯数据:它们将会影响控制流,这也是测试的重点部分。
长度:它的数值理应随着文件长度增加而增大,若未变化不同程序执行流将会出现很多种可能的变化,如校验出错,程序崩溃等,但长度正确时执行流应该是不会变化的。
。。。。。。。。。。。。。
从这里可以看出,不同属性的数据对程序执行流的影响是不同的,于是可以根据程序的执行路径反向推测出相应数据的属性!
检测程序执行流 怎么才能够知道程序执行的状态?AFL使用了插装技术,它可以在编译时就向程序中插入一些代码,执行到这些代码时就告知AFL,每段代码有唯一的编号以标识此位置,这样AFL就能通过编号知道程序执行到了哪个位置(路径),阅读源码,在编译时插桩:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 static void add_instrumentation (void ) if (input_file) { inf = fopen(input_file, "r" ); if (!inf) PFATAL("Unable to read '%s'" , input_file); } else inf = stdin ; outfd = open(modified_file, O_WRONLY | O_EXCL | O_CREAT, 0600 ); if (outfd < 0 ) PFATAL("Unable to write to '%s'" , modified_file); outf = fdopen(outfd, "w" ); if (!outf) PFATAL("fdopen() failed" ); while (fgets(line, MAX_LINE, inf)) { if (!pass_thru && !skip_intel && !skip_app && !skip_csect && instr_ok && instrument_next && line[0 ] == '\t' && isalpha (line[1 ])) { fprintf (outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE)); instrument_next = 0 ; ins_lines++; } fputs (line, outf); }
而被插入的代码,以32位为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 static const u8* trampoline_fmt_32 = "\n" "/* --- AFL TRAMPOLINE (32-BIT) --- */\n" "\n" ".align 4\n" "\n" "leal -16(%%esp), %%esp\n" "movl %%edi, 0(%%esp)\n" "movl %%edx, 4(%%esp)\n" "movl %%ecx, 8(%%esp)\n" "movl %%eax, 12(%%esp)\n" "movl $0x%08x, %%ecx\n" "call __afl_maybe_log\n" "movl 12(%%esp), %%eax\n" "movl 8(%%esp), %%ecx\n" "movl 4(%%esp), %%edx\n" "movl 0(%%esp), %%edi\n" "leal 16(%%esp), %%esp\n" "\n" "/* --- END --- */\n" "\n" ;
可见到插入的代码即__afl_maybe_log(random() % MAP_SIZE),这个函数的实现会在下面贴上,总之它对每一个点插入的代码(参数)都不一样,代码是随机的,即不考虑碰撞的情况下执行被插入的代码时可以唯一的确定程序当前运行位置。
记录执行流 现在已经知道怎么获取程序执行到的每一个位置了,但怎么高效的存储与方便后续利用?首先明确此阶段目的是用最少的测试用例完成最多的代码覆盖,于是我们需要记住每次执行的路径,若下一次的输入得到了同样的路径那就将其丢弃,相反若得到新的路径将此次输入保留,这里就要记录程序执行的路径了,最简单直观的方式就是使用一个单链表:
1 2 3 4 struct node { ADDR addr; struct node * nextAddr ; }
但是这会存在很多弊端,首先将会极大浪费空间,而且搜索效率极其低下,最后很多相似的路径其实是可以合并且无伤大雅的,例如多执行了一次循环操作,但在这种存储方式下将会是截然不同的两条路径,产生多条冗余的路径。afl采用另一种巧妙的方式,它对路径的记录并没有那么严格,它维护了一张Map表,将执行流以二元组为单位映射到一个地址,并在这个位置记录这种二元组出现的次数,例如:
在这个执行流中,<A,B><B,D><D,F><F,B>这四个二元组就能表示程序的局部执行顺序,将每个二元组做hash映射到一个Map里面,此时Map里面大部分数据是0,<A,B><D,F><F,B>这三个单元的数据是1,<B,D>这个单元的数据是2,这里的数字就表示对应的这种相邻调用执行了多少次,显然这里有两个问题:
1 2 3 4 5 6 7 8 Branch cnt | Colliding tuples | Example targets ------------+------------------+----------------- 1,000 | 0.75% | giflib, lzo 2,000 | 1.5% | zlib, tar, xz 5,000 | 3.5% | libpng, libwebp 10,000 | 7% | libxml 20,000 | 14% | sqlite 50,000 | 30% | -
当分支数低于20000时碰撞都还在一个比较小的范围。
现在再看看afl实际的实现,对<A,B>这条路径进行记录,在选择hash函数做hash(A,B)=C运算时,最简单有效的转换方法就是异或运算,它能很好的利用两个数的各个有效位(可以对比或加与运算 ),但是这类运算都①满足交换律于是不能分辨<A,B>与<B,A> ,另外异或运算有一个特点就是②任意数与本身异或结果为0不能分辨<A,A>与<B,B> 。为了解决这个问题,可以对二元组的第一个值(路径链的前驱)进行移位操作,相当于认为添加了方向识别(当然这会引入新问题,但是解决了主要问题 ):
1 2 3 cur_location = <COMPILE_TIME_RANDOM>; shared_mem[cur_location ^ prev_location]++; prev_location = cur_location >> 1 ;
以上,就完成了程序流监控与记录的任务了。
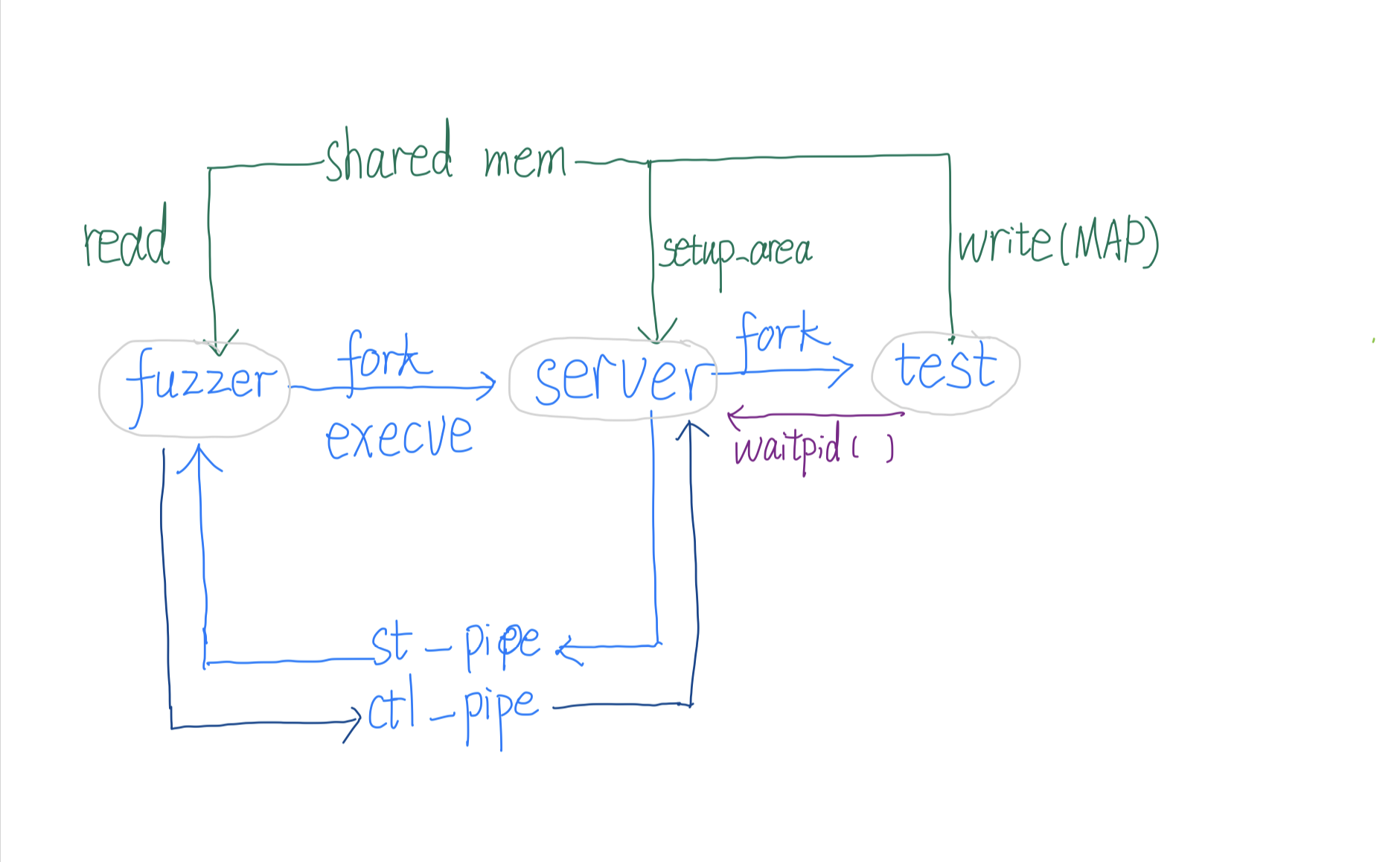
架构 Linux下执行一个程序分为两步:先fork创建新进程,再使用execve载入目标程序,其中前者主要创建PCB并处理相关资源,对内存也使用写时复制故代价较小,而后者需要读取,解析,链接目标程序,代价较大。在进行fuzzing时,fuzzer和被测试程序不同,但fuzzer创建的被测试进程都一样的,因此为了节省资源被测试进程不应该由fuzzer直接创建而是由fuzzer创建子进程后,子进程调用execve装载被测程序后,再以此状态为基础进行fork,如图:
fuzzer :即直接执行afl-fuzz产生的进程。它负责控制fuzzingserver :由fuzzer使用fork和execve(target)新建的子进程,它其实是被测程序了,但是它本身不会将测试用例作为输入去执行程序,它将作为一个母体,接受fuzzer的指令,fork出子进程去做真正的测试,并将子进程的pid和其退出状态传递给fuzzer。test :由server使用fork得到的子进程,它将用afl生成的测试用例为输入,执行原有程序逻辑,并将返回的结果报告给父进程(server),再由父进程报告给父进程的父进程(fuzzer)。
通信 如上图三个对象之间需要通信,afl采用了匿名管道,信号和共享内存三种方式:
匿名管道 :在fuzzer中定义了两个匿名管道:st_pipe[2], ctl_pipe[2],前者传输状态(数据),方向为server到fuzzer,后者传入指令,方向为fuzzer到server。信号 :server在创建子进程后会使用waitpid等待子进程的信号或事件,得到其改变后的状态后将它传递给fuzzer共享内存 :fuzzer要获取test的执行情况,而这些是由test记录的,所以在test结束等事件发生后,fuzzer要获取这些执行流,afl使用共享内存,在fuzzer中申请了一片共享内存用于存储MAP并将其shm_id设置到环境变量中,server会通过环境变量得到shm_id再次打开这片共享内存,之后test就能直接使用它向它里面记录路径,而fuzzer直接可以读test记录的路径了。
(具体的代码见执行部分代码分析。 )
执行 先来看看在编译时还被插入到被测程序中的代码,即被测试程序会执行的代码,其实这段汇编代码 可以把它看作__afl_maybe_log函数的定义:AFL_VARS实际被定义在main_payload_32的末尾,为了阅读方便单独提出,它们是定义的一些变量:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 "\n" ".AFL_VARS:\n" "\n" " .comm __afl_area_ptr, 4, 32\n" " .comm __afl_setup_failure, 1, 32\n" #ifndef COVERAGE_ONLY " .comm __afl_prev_loc, 4, 32\n" #endif " .comm __afl_fork_pid, 4, 32\n" " .comm __afl_temp, 4, 32\n" "\n" ".AFL_SHM_ENV:\n" " .asciz \"" SHM_ENV_VAR "\"\n"
main_payload_32的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 static const u8* main_payload_32 = ".text\n" ".att_syntax\n" ".code32\n" ".align 8\n" "\n" "__afl_maybe_log:\n" "\n" " lahf\n" " seto %al\n" " movl __afl_area_ptr, %edx\n" " testl %edx, %edx\n" " je __afl_setup\n" "\n" "__afl_store:\n" "\n" " /* Calculate and store hit for the code location specified in ecx. There\n" " is a double-XOR way of doing this without tainting another register,\n" " and we use it on 64-bit systems; but it's slower for 32-bit ones. */\n" "\n" #ifndef COVERAGE_ONLY " movl __afl_prev_loc, %edi\n" " xorl %ecx, %edi\n" " shrl $1, %ecx\n" " movl %ecx, __afl_prev_loc\n" #else " movl %ecx, %edi\n" #endif "\n" #ifdef SKIP_COUNTS " orb $1, (%edx, %edi, 1)\n" #else " incb (%edx, %edi, 1)\n" #endif "\n" "__afl_return:\n" "\n" " addb $127, %al\n" " sahf\n" " ret\n" "\n" ".align 8\n" "\n" "__afl_setup:\n" "\n" " cmpb $0, __afl_setup_failure\n" " jne __afl_return\n" "\n" " pushl %eax\n" " pushl %ecx\n" "\n" " pushl $.AFL_SHM_ENV\n" " call getenv\n" " addl $4, %esp\n" "\n" " testl %eax, %eax\n" " je __afl_setup_abort\n" "\n" " pushl %eax\n" " call atoi\n" " addl $4, %esp\n" "\n" " pushl $0 /* shmat flags */\n" " pushl $0 /* requested addr */\n" " pushl %eax /* SHM ID */\n" " call shmat\n" " addl $12, %esp\n" "\n" " cmpl $-1, %eax\n" " je __afl_setup_abort\n" "\n" " /* Store the address of the SHM region. */\n" "\n" " movl %eax, __afl_area_ptr\n" " movl %eax, %edx\n" "\n" " popl %ecx\n" " popl %eax\n" "\n" "__afl_forkserver:\n" "\n" " pushl %eax\n" " pushl %ecx\n" " pushl %edx\n" "\n" " /* Phone home and tell the parent that we're OK. (Note that signals with\n" " no SA_RESTART will mess it up). If this fails, assume that the fd is\n" " closed because we were execve()d from an instrumented binary, or because\n" " the parent doesn't want to use the fork server. */\n" "\n" " pushl $4 /* length */\n" " pushl $__afl_temp /* data */\n" " pushl $" STRINGIFY((FORKSRV_FD + 1 )) " /* file desc */\n" " call write\n" " addl $12, %esp\n" "\n" " cmpl $4, %eax\n" " jne __afl_fork_resume\n" "\n" "__afl_fork_wait_loop:\n" "\n" " /* Wait for parent by reading from the pipe. Abort if read fails. */\n" "\n" " pushl $4 /* length */\n" " pushl $__afl_temp /* data */\n" " pushl $" STRINGIFY(FORKSRV_FD) " /* file desc */\n" " call read\n" " addl $12, %esp\n" "\n" " cmpl $4, %eax\n" " jne __afl_die\n" "\n" " /* Once woken up, create a clone of our process. This is an excellent use\n" " case for syscall(__NR_clone, 0, CLONE_PARENT), but glibc boneheadedly\n" " caches getpid() results and offers no way to update the value, breaking\n" " abort(), raise(), and a bunch of other things :-( */\n" "\n" " call fork\n" "\n" " cmpl $0, %eax\n" " jl __afl_die\n" " je __afl_fork_resume\n" "\n" " /* In parent process: write PID to pipe, then wait for child. */\n" "\n" " movl %eax, __afl_fork_pid\n" "\n" " pushl $4 /* length */\n" " pushl $__afl_fork_pid /* data */\n" " pushl $" STRINGIFY((FORKSRV_FD + 1 )) " /* file desc */\n" " call write\n" " addl $12, %esp\n" "\n" " pushl $0 /* no flags */\n" " pushl $__afl_temp /* status */\n" " pushl __afl_fork_pid /* PID */\n" " call waitpid\n" " addl $12, %esp\n" "\n" " cmpl $0, %eax\n" " jle __afl_die\n" "\n" " pushl $4 /* length */\n" " pushl $__afl_temp /* data */\n" " pushl $" STRINGIFY((FORKSRV_FD + 1 )) " /* file desc */\n" " call write\n" " addl $12, %esp\n" "\n" " jmp __afl_fork_wait_loop\n" "\n" "__afl_fork_resume:\n" "\n" " /* In child process: close fds, resume execution. */\n" "\n" " pushl $" STRINGIFY(FORKSRV_FD) "\n" " call close\n" "\n" " pushl $" STRINGIFY((FORKSRV_FD + 1 )) "\n" " call close\n" "\n" " addl $8, %esp\n" "\n" " popl %edx\n" " popl %ecx\n" " popl %eax\n" " jmp __afl_store\n" "\n" "__afl_die:\n" "\n" " xorl %eax, %eax\n" " call _exit\n" "\n" "__afl_setup_abort:\n" "\n" " /* Record setup failure so that we don't keep calling\n" " shmget() / shmat() over and over again. */\n" "\n" " incb __afl_setup_failure\n" " popl %ecx\n" " popl %eax\n" " jmp __afl_return\n"
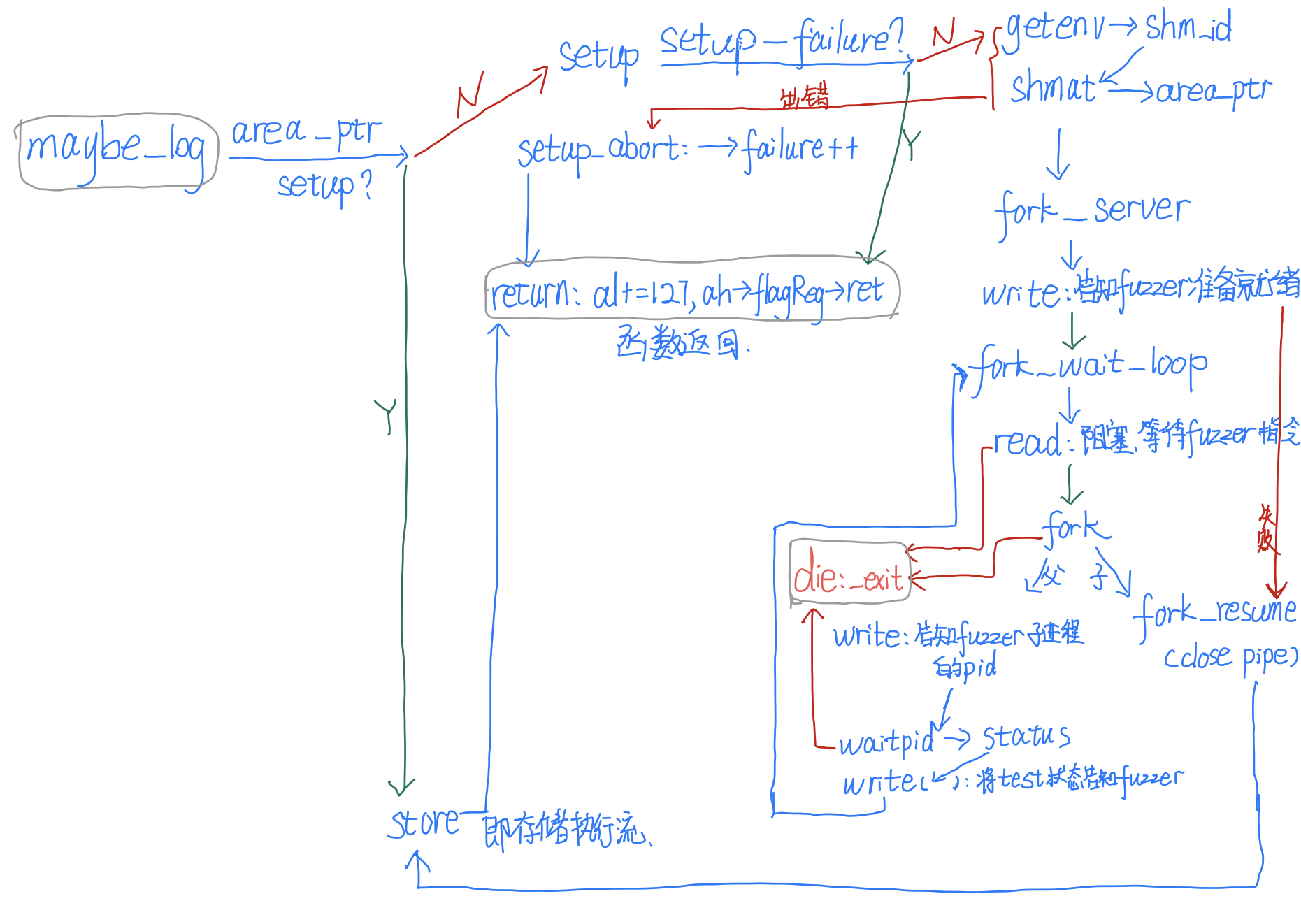
可以画个流程图便于理清逻辑:__afl_maybe_log时,__afl_area_ptr未被设置,就会进入__afl_setup处,它设置完会进入__afl_fork_server处,之后该进程会一直循环等待fuzzer的指令,收到指令就会fork出子进程test,test再次调用__afl_maybe_log时由于__afl_area_ptr已被设置不会再进入这些代码,而会直接进入__afl_store存储路径并返回。fuzzer部分的其他代码以后再分析,先看看最核心的测试用例生成代码。 )
生成测试用例 首先明白我们已经能够知道测试用例的结果了
interest 手动测试时我们总会输入一些有意思的值,如边值,这是有很大概率能使程序出错的值,因此自动工具也不能错过它:
1 2 3 4 5 6 7 8 9 /* List of interesting values to use in fuzzing. */ #define INTERESTING_8 \ -128, /* Overflow signed 8-bit when decremented */ \ -1, /* */ \ 0, /* */ \ 1, /* */ \ 16, /* One-off with common buffer size */ \ 32, /* One-off with common buffer size */ \ 64, /* One-off with common buffer size */ \ 100, /* One-off with common buffer size */ \ 127 /* Overflow signed 8-bit when incremented */ #define INTERESTING_16 \ -32768, /* Overflow signed 16-bit when decremented */ \ -129, /* Overflow signed 8-bit */ \ 128, /* Overflow signed 8-bit */ \ 255, /* Overflow unsig 8-bit when incremented */ \ 256, /* Overflow unsig 8-bit */ \ 512, /* One-off with common buffer size */ \ 1000, /* One-off with common buffer size */ \ 1024, /* One-off with common buffer size */ \ 4096, /* One-off with common buffer size */ \ 32767 /* Overflow signed 16-bit when incremented */ #define INTERESTING_32 \ -2147483648LL, /* Overflow signed 32-bit when decremented */ \ -100663046, /* Large negative number (endian-agnostic) */ \ -32769, /* Overflow signed 16-bit */ \ 32768, /* Overflow signed 16-bit */ \ 65535, /* Overflow unsig 16-bit when incremented */ \ 65536, /* Overflow unsig 16 bit */ \ 100663045, /* Large positive number (endian-agnostic) */ \ 2147483647 /* Overflow signed 32-bit when incremented */ static s8 interesting_8[] = { INTERESTING_8 }; static s16 interesting_16[] = { INTERESTING_8, INTERESTING_16 }; static s32 interesting_32[] = { INTERESTING_8, INTERESTING_16, INTERESTING_32 };
dictionary 上面的大概率值是通用的,对于特定程序我们可能会知道某些数据是有特殊意义的,alf可以使用自己定义的特值(即词典):
注意使用不同种方法可能会生成相同的用例,当遇到已经被测试过的用例将跳过不再重复测试它。
effector map afl-analyze处已经说到程序能推测一种对执行流无影响的数据,对这种数据进行变异将是没有多大意义的,这里把它定义为无效的,它的具体识别方法是若一byte数据完全反转都不改变执行流,那么就认为它是无效的。为此afl可以生成一张effector map表 表明可能的有效数据的区域,以后就只对有效区域的数据进行变异。有三种情况
1 2 3 4 #define EFF_MIN_LEN 128 #define EFF_MAX_PERC 90
bitflip 这将按照一定的规律反转比特位
arithmetic 对数据进行算术运算
havoc 进行随机次变异,每次变异随机选择一种变异方式。
splice 选择两个差别较大的用例,随机选择一个位置将它们收尾分割,交叉组合形成新的用例.
使用 afl支持在编译时插桩也支持对可执行的二进制文件进行fuzz,如使用afl-gcc对源文件进行编译:
1 ./configure CC="afl-gcc" CXX="afl-g++" --disable -shared; make
现在开始测试,先新建一个测试用例目录,可以在这个目录自定义一些用例文件作为输入,另外afl支持很多种生成测试用例的方式,包括根据反馈结果启发式生成与哑模式的毫无规律生成,其中我们可以先去自己定义一些规范的输入作为种子,这样可以减少才开始测试的时间:
1 afl-fuzz -i in_dir- -o out_dir ./target
优化 使用RAM盘 因为afl将会频繁的写文件,这样能够减少IO次数,这在速度上不会有显著提升但是但是能保护硬盘延长使用寿命,当然虚拟盘断电就没了要注意及时取出。
1 2 mkdir /tmp/afl-ramdisk && chmod 777 /tmp/afl-ramdisk mount -t tmpfs -o size=512M tmpfs /tmp/afl-ramdisk
测试用例 样例应该足够小足够
测试对象 插桩时只对需要检测的模块插桩,若多种程序使用了要检测的模块,选用速度最快的那个程序。
参考
[0]Skyfire: Data-Driven Seed Generation for Fuzzing AFL技术白皮书 djpeg样例 say-hello-to-afl-analyze status-screen perf_tips AFL内部实现细节小记 AFL文件变异一览