
不定期更新汇编语言的一些笔记除夕快乐
数值表示
真值就是我们平时使用的数值,机器数为存放在内存中的数,它的小数点实际上并不存在或者说并没有被存储,只是人为的规定怎么读取这种数。
原码:将正负位表示为01,即第一位为符号位。正为0负为1,其他部分和真值值部分一样。(+0和-0原码是不一样的)
补码:正数的补码为它本身,负数的补码为原码数值部分取反再加1.(-0和+0补码一样,且补码能表示的范围会大一),同样,已知补码求原码也是,正数不变,负数数值部分取反再加1.
反码:正数的反码是他本身,负数的反码为数值部分取反。(-0和+0的反码不一样)
Y的补码与-Y的补码转换关系为:-Y的补为Y的补码每一位(包括符号位)取反后加一
移码:补码加上模。(用于比较数的大小,当然啦:-0和+0一样)
截止目前,遇到的都还是定点数,即纯小数或整数。那么float,double是什么呢?就是下面的浮点数了、、、、、
浮点数的表示:
浮点数的范围: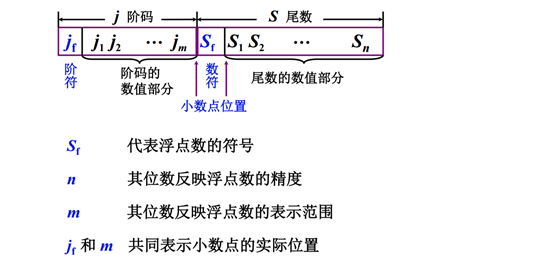
最大的正数就是阶符为正,阶值全为1,数符为0,数值全为1.其他同理。于是,当数值全为0,或者阶值超出了能表示的范围就代表为0啦。
移位运算
不多说,算数移位就是有符号的移位: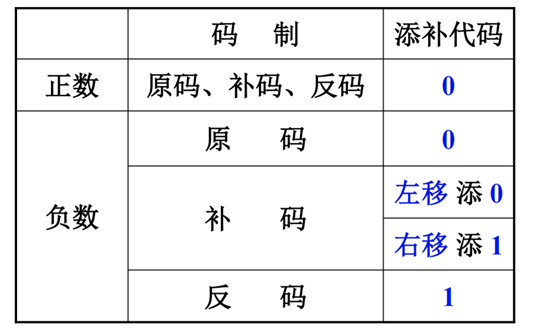
逻辑移位是没有符号的移位,全部补0
工具与风格
汇编有指令与伪指令,伪指令是由汇编器解释的,现在简述一下汇编工具,本篇涉及三种汇编工具:nasm,masm,gas,其中第二个应该是我们最熟悉的,上课用的就是这个,现在来说下它们区别–它们支持的伪指令不同,它们支持的语法风格不同。
- 语法风格,主要是intel风格与AT&T风格,前者是上课讲的那种,后者在下文有描述。nasm与masm使用Intel风格,而gas使用AT&T风格。
- nasm是开源的,masm是微软的,Linux下写代码更常用到nasm,但是C内联代码又需要AT&T风格,因为GCC用的gas汇编(下文会有描述)。
M/NASM
nasm区分大小写,masm不区分,下面记录的主要是伪指令部分,因为它们是由汇编工具识别的。
定义节区
masm:
1 | ASSUME DS: |
nasm:
1 | section .data |
定义数据
- 对内存数据:
| nasm | masm |
|---|---|
| byte | byte |
| word | word |
| dword | dword |
| qword | qword |
| oword | xmmword |
1 | mov eax,byte [ebx] ;nasm |
- 定义数据:
1 | 都使用db,dw,dd,dq,do |
- 定义常量:
1 | a equ 0 ;都一样 |
- 定义未初始数据:
| nasm | masm |
|---|---|
| resb | db ? |
| resw | dw ? |
| resd | dd ? |
| resq | dq ? |
- 定义数组:
1 | times 100 db 0 ;nasm |
- 数值表示:
| 进制 | 前缀 | 后缀 |
|---|---|---|
| 10 | 0d | d[可省略] |
| 8 | 0o | o |
| 16 | 0x | h |
| 2 | 0b | b |
- 字符串表示:
1 | 'wulalalal' |
它支持转义符,以’/‘修饰,当然它在末尾表示换行。
包含其他文件
1 | incbin "bin",128,512 |
其他变量
$:当前指令位置
$$:当前节区位置
编译
1 | nasm -f elf64 -o hello.o hello.asm |
预处理指令
1 | $ :当前指令地址 |
宏
- 单行
1 | %define macro_name(parameter) value |
- 多行
1 | %macro macro_name number_of_parameters |
在宏里,标签必须以%%开始,例如:
1 | %macro PRINT 1 |
结构体
声明结构体:
1 | struc person |
定义结构体:
1 | section .data |
Intel Code
寄存器
通用寄存器
EAX(AX,AH,AL):(针对操作数和结果数据的)累加器
EBX:(DS段中的数据指针)基址寄存器
ECX:(字符串和循环操作的)计数器
EDX:(I/O指针)数据寄存器
ESI:(字符串操作源指针)源变址寄存器
EDI:(字符串操作目标指针)目的变址寄存器
EBP:(SS段中栈内数据指针)扩展基址指针寄存器
ESP:(SS段中栈指针)栈指针寄存器
标志寄存器
EFLAGS:标志寄存器
这里只需要记录标志寄存器:
- CF表示进位或借位,针对无符号整数,判断是否超出表达范围。
- OF表示溢出,针对有符号整数,溢出符号就反啦,其实有符号与无符号一个区别就是最高位是符号还是数值,当是数值时,最高位的高位发生变化就是CF,而是符号时,最高位收到数值运算影响就是OF,计算机并不知道是否有符号,逻辑有程序员决定。
- ZF,SF,PF分别表示上次运算结果为0,最高位为1,为1的位数为偶数个。
指令指针寄存器
EIP:(存放下一条要执行指令地址的)指令指针寄存器
段寄存器
CS:代码段寄存器
DS:数据段寄存器
SS:栈段寄存器
ES:附加(数据段)寄存器
FS:数据段寄存器
GS:数据段寄存器
寻址方式
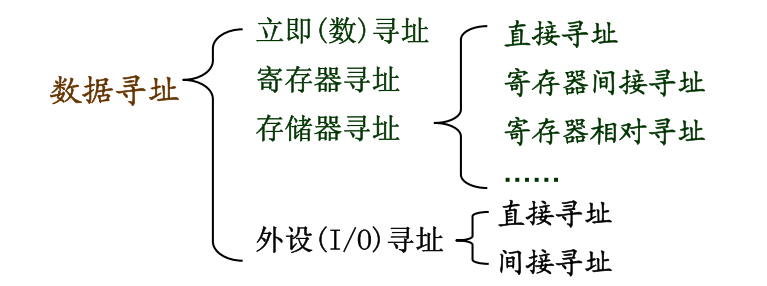
指令
数据传送
除非操作标志寄存器,否则不影响标志位:
MOV,XCHG,PUSH,POP,LEA,MOVSX,MOVZX,PUSHA(AX,CX,DX,BX,SP,BP,SI,DI依次入栈),POPA,PUSHAD(EAX,ECX,EDX,EBX,ESP,EBP,ESI,EDI依次入栈),POPAD,BSWAP(改变32寄存器的字节序),LAHF(将标志载入AH),SAHF,PUSHHF,POPF,PUSHD,POPD(32标志)
算数运算
ADD,ADC,INC(不影响CF)
SUB,SBB,DEC(不影响CF)
NEG
CMP(只影响标志位)
MUL(AH,AL/DX,AX分别存高位与低位,CF置位表示高位有效),IMUL
DIV,IDIV(商AX,余数DX)
CBW(字节转字),CWD(字转双字,AX扩展到DX),CWDE(字转双字,AX到EAX),CDQ(双字扩展,EAX到EDX)
位操作
AND,OR,NOT,XOR(这些都会使OF=CF=0并影响其他标志位)
TEST(只影响标志位)
SHL,SAL:一样,最低位补0,高位进CF (注A:Arithmetic)
SHR,SAR:算数高位不变,逻辑高位补0,低位都进CF
ROL,ROR:循环左移右移,循环时将最低或最高位额外的也放入EFLAGS的CF
RCL,RCR:即将CF与寄存器串联(注C:Carry flag)
TEST
转移指令
短转移(SHORT):-128~127字节
近转移(NEAR):不改变CS的转移
远转移(FAR):段间转移
1 | JMP |
循环指令
1 | LOOP lable ;ecx=0时结束,先减后判断 |
串操作
相关寄存器:
DS:SI 源串段寄存器 :源串变址.
ES:DI 目标串段寄存器:目标串变址.
CX 重复次数计数器.
AL/AX 扫描值.
D标志 0表示重复操作中SI和DI应自动增量; 1表示应自动减量.
Z标志 用来控制扫描或比较操作的结束.
指令:
1 | MOVS(MOVSB,MOVSW,MOVSD) |
其他
INT,IRET,HLT,NOP,STC(CF=1),CLC(CF=0),CMC(~CF),STD(DF=1,递减),CLD(DF=0,递增),STI(中断允许使能),CLI(中断允许失能)
AT&T Code
在Linux中常见的是AT&T语法,这和学校学的汇编风格有些许不同,这里在也记录一下:
- 操作码明确指明了操作位数,在Intel中,指令中涉及内存,例如mov,xor,add,cmp等,都是在内存操作数前使用word ptr、byte ptr等指定操作数大小,而在AT&T中就是使用操作符后接操作数大小,如下:
1 | movl $10,%eax ;AT&T |
详细如下:
| C声明 | GAS后缀 | 大小(字节) |
|---|---|---|
| char | b | 1 |
| short | w | 2 |
| (unsigned) int / long / char* | l | 4 |
| float | s | 4 |
| double | l | 8 |
| long double | t | 10/12 |
- 目的操作数位置发生变化,如下可以看出NASM中目的在后源在前:
1 | mov eax,ebx ;Intel |
- 寻址方式发生变化:
1 | movl $0x12345678(%ebx,%edi,4),%eax |
$0x12345678是基址,ebx是相对基址偏移,edi为序号,4为大小,即EA为$0x12345678+ebx+edi*4,当然在实际使用时并不一定每一位都用上,只要保持格式即可,例如:
1 | movl (%ebx,%edi,4),%eax ;EA=ebx+edi*4 |
另外,间接寻址时,NASM使用()而不是MASM的[]
1 | movl (%ebx),%eax ;AT&T |
- 常数、常量前使用
$修饰,寄存器使用%修饰,地址前使用*修饰,另外在N语法中16进制数是以h结尾而A语法中是以0x作为前缀:
1 | movl $10,%eax |
- 一条常用的指令
1 | leave ;平衡栈帧 |
- 节区使用
.sectionName定义:
1 | .data |
- 注释也有不同
1 | //NASM |
- 在定义节区时,不需要section修饰,并且
_global改为.global
GCC内联汇编
在C语言中使用汇编有三种方法:
- 单独编写汇编语言为对象文件,导出函数在C中调用
1
2nasm -f elf64 -o casm.o casm.asm
gcc casm.o casm.c -o casm - 编译C语言文件为对象文件,在汇编语言中调用
1
2
3gcc -c casm.c -o c.o
nasm -f elf64 casm.asm -o casm.o
ld -dynamic-linker /lib64/ld-linux-x86-64.so.2 -lc casm.o c.o -o casm - 内联汇编,即直接在C语言代码中插入汇编语言代码。
这里面第三种最常用,下面记录这种,需要注意,这并不是汇编的语法,而是GNU assembler的语法。
基本形式
格式如下,直接在字符串里面写汇编语句,每条语句以\n\t结束,当asm为C里面已定义的关键字,可以使用__asm__代替:
1 | asm("movl %ecx %eax \n\t" |
这会存在一个大问题,就是汇编语句用到的寄存器里面之前存放的值将会被破坏,或者由于优化之前对内存的操作并没写回内存但是内联汇编语句需要访问此内存造成值错误,因为GCC对C代码的编译优化什么的是作为一个整体考虑的,不会出现问题但是插入汇编代码对于GCC来说是不可见的,下面的扩展语法就是为了解决这个问题的。
扩展形式
样板如下:
1 | asm [volatile] ( assembler template |
首先是volatile关键字,在C语言中遇到过,在有的时候它能神奇的保证程序不会出错,它的作用就是对内存的操作始终如实进行而不使用缓存。接下来就是大头,小括号里面,第一项就是基本形式里面的,它是必须要写的,后面的都是可选项,当然若是在后面的三个可选项中,选择后面的项前面的项必须写出来,至少要使用:来占位,而选择前面的项就可以不写后面的了,例如:
1 | asm ( assembler template |
现在具体说下后面三个可选项的含义,后三项的前两项是输出操作数与输入操作数,最后一项代表汇编指令中会使用的寄存器,换句话说会破坏的寄存器,这样GCC就知道这段内联汇编会破坏哪些寄存器了,就不会在这些寄存器里面存放有用的数据,例如先将这里面的寄存器数据备份到栈上,合适时候再恢复,明显的,GCC能够知道输入与输出操作数指定的寄存器是会被破坏的,所以在clobbered list里面不必再写他们了。那么输入输出操作数怎么写呢?如下:
1 | int a=10, b; |
最后一个clobbered list里写受影响的寄存器,对于标志寄存器,使用cc,内存使用memory,在前面的输入输出中,每个操作数之间使用,分割,操作数被放在()里,前面加上修饰符(约束)如上面的”=r”,”m”这种,其中输出操作数前面多了=,它表示操作数只写,至于”r,m”这些的意思如下:
| 修饰符 | 操作数的类型 |
|---|---|
| r | 通用寄存器 |
| g | 寄存器,内存,立即数 |
| f | 浮点寄存器 |
| a | %eax, %ax, %al |
| b | %ebx, %bx, %bl |
| c | %ecx, %cx, %cl |
| d | %edx, %dx, %dl |
| S | %esi, %si |
| D | %edi, %di |
| m | 内存 |
| 0 | 数字代表和输出操作数的第0个一样 |
注:对于内存型的操作数,若指定修饰为寄存器则先缓存在寄存器里面再存到内存位置,还有一些修饰符详见参考[3]
到目前为止,还没有涉及括号里的第一部分-汇编指令部分,既然可以指定输入与输出,那么一定能在汇编指令里面体现它,即将所有操作数(包括输入与输出)从第0号开始排序,在语句中使用%n即可引用对应操作数,而其中的标签就需要使用$$来修饰,寄存器也需要%%来修饰。
参考
[1]哈尔滨工业大学-《计算机组成原理-下》
[2]say-hello-to-x8664-assembly
[3]GCC-Inline-Assembly-HOWTO
[4]8088 汇编速查手册
[5]郑州大学- 《汇编语言程序设计》
[6]电子科技大学- 《汇编语言程序设计》